Детская Неврологическая Клиника Прогноз: Цены, Запись Онлайн
Это специализированная детская неврологическая клиника, которая находится в Санкт-Петербурге и занимается диагностикой и лечением детей с нарушениями развития. Клиника создана в 1988 году детским врачом-неврологом Олегом Игоревичем Ефимовым.
В детской клинике «Прогноз» любой ребенок в возрасте от 1 месяца до 16 лет может получить консультацию высококвалифицированных специалистов: невролога, психолога, логопеда и пройти диагностику.
В тесном контакте с врачами работают педагоги и реабилитологи центра «Логопрогноз», где проводится немедикаментозная реабилитация и развивающие занятия.
В чем особенность клиники «Прогноз»?
Самая важная отличительная особенность клиники – аппаратная диагностика. В клинике используется современное специализированное оборудование, которое позволяет выявить нарушения в работе мозга ребенка и назначить эффективное и безопасное лечение.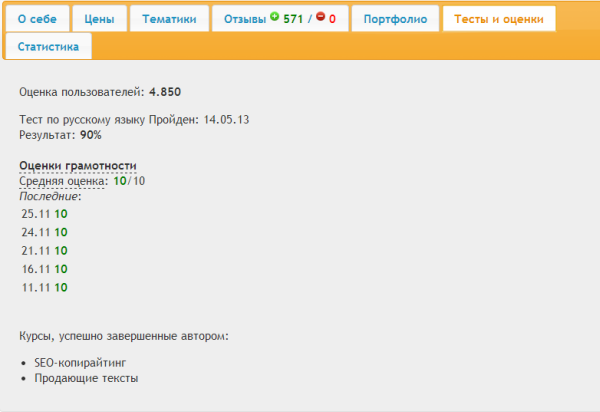
Каждый месяц врачи клиники проводят также диагностику в Москве. Информацию о датах следующего приема вы найдете в разделе «Диагностика в Москве» на официальном сайте клиники.
С какими проблемами обращаются в детский неврологический центр «Прогноз»?
Специализацией клиники являются нарушения развития речи, внимания, общения, школьные трудности. Чаще всего к нам обращаются со следующими диагнозами:
- Аутизм
- Алалия
- ЗПРР, ЗПР
- СДВГ
- синдром Дауна
- дислексия
- дисграфия
В клинике есть отделение диагностики и реабилитации детей от 2 месяцев до 2 лет «Прогноз-Малютка».
Для чего обращаются в клинику?
Любого ребенка нужно периодически показывать неврологу, но есть возрастные периоды или ситуации, когда это особенно важно.
- В первые месяцы жизни ребенка, особенно если была тяжелая беременность или тяжелые роды
- В три года
- Перед школой
- При задержке и нарушениях речевого и коммуникативного развития
- Если есть школьные трудности: проблемы с вниманием, чтением, письмом, счетом
- Если у ребенка нарушения сна, жевания, глотания, энурез, тики.
Какие методы диагностики используются в клинике «Прогноз»?
Наша цель — выявление конкретных слабых звеньев в работе нервной системы. Затем мы можем воздействовать именно на них во время реабилитации и лечения. Для этого проводится комплексная неврологическая диагностика, в которую входят следующие методики:
- ЭЭГ – оценка электрической активности мозга
- АСВП – оценка функционального состояния ствола мозга и проведения звуковой информации структурами ствола.

- УЗДГ – оценка кровоснабжения головы и шеи
По показаниям назначается и проводится в клинике ночной видео ЭЭГ мониторинг
Только в клинике «Прогноз» проводится уникальная диагностика вестибулярной системы и баланса, которая включает в себя следующие методики:
- Поствращательный нистагм — оценка функции полукружных каналов
- ВМВП – оценка функции отолитов
- Айтрекинг – оценка вестибулоокулярного рефлекса и оптокинетического нистагма
- Постурография – оценка сенсорной интеграции для сохранения баланса
Какие методы лечения используются?
Мы отдаем предпочтение немедикаментозным методам лечения. Информацию о них вы найдете в разделе «методы» на официальном сайте клиники «Прогноз» и на официальном сайте центра «Логопрогноз». Все методы безопасны для здоровья ребенка, научно обоснованы и уже доказали свою эффективность.
Врач невролог назначает также курс медикаментозного лечения на несколько месяцев. Медикаментозное лечение родители проводят дома.
Обратите внимание, что реабилитация в детском неврологическом центре проводится только интенсивными курсами – 16 дней. Программа реабилитационного курса составляется после диагностики на совместной консультации невролога и логопеда-реабилитолога.
Стоит ли прямо сейчас записаться на диагностику?
Научные исследования подтверждают, что ранняя диагностика и специализированная неврологическая помощь дают прекрасные результаты. Не нужно ждать, когда ребенку будет 5 или 7 лет. В этом случае понадобится гораздо больше времени и усилий для того чтобы нормализовать работу его нервной системы. Лучше начать помощь как можно раньше.
Комплексная аппаратная диагностика в клинике «Прогноз» позволит вам за 3 – 4 часа получить полную информацию о функциональном состоянии мозга ребенка. Если вы приезжаете из другого города, то диагностику можно пройти непосредственно перед курсом реабилитации.
Если вы приезжаете из другого города, то диагностику можно пройти непосредственно перед курсом реабилитации.
Информацию о стоимости услуг вы найдете в разделе «цены»на официальном сайте клиники «Прогноз». Запись на консультации, диагностику и бронирование мест на интенсивный курс реабилитации осуществляется через форму записи на сайте или по телефону.
Чем раньше выявлены причины нарушений, тем лучше прогноз развития ребенка. Не откладывайте на потом, не ждите, что ребенок «перерастет» проблемы, запишитесь на диагностику и консультацию детского невролога.
Методика визуальной поддержки поможет подготовить ребенка к новому событию. С помощью «социальной истории» Ваш ребенок увидит как именно это происходит. Когда события предсказуемы, уровень тревожности снижается.
Прочитав эту статью, Вы узнаете как подготовить ребенка к занятиям в наушниках.
Методика «Интеллектуальная лабильность»
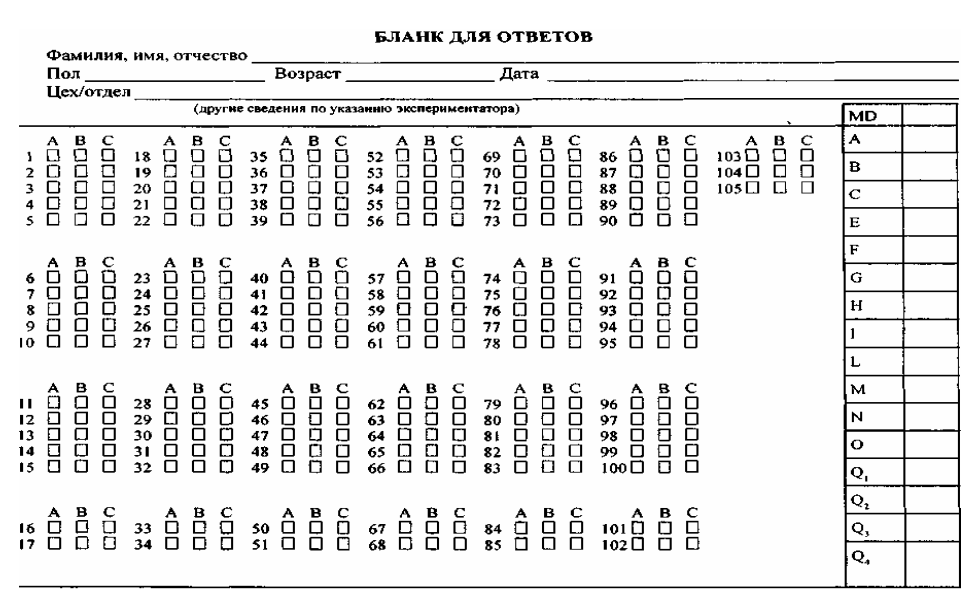
Методика «Интеллектуальная лабильность»Тест рекомендуется использовать с целью прогноза успешности в профессиональном обучении, освоении нового вида деятельности и оценки качества трудовой практики.
Тест требует от испытуемого высокой концентрации внимания и быстроты действий. Обследуемые должны в ограниченный отрезок времени (несколько секунд) выполнить несложные задания, которые будет зачитывать экспериментатор. Обследование можно проводить как индивидуально, так и в группе, возможно использование магнитофона. Каждому испытуемому выдается специальный бланк.
Инструкция
- (квадрат номер 1) Напишите первую букву имени Сергей и последнюю букву первого месяца года.
- (квадрат номер 4) Напишите слово ПАР так, чтобы любая одна буква была написана в треугольнике.
- (квадрат 5) Разделите четырехугольник двумя вертикальными и двумя горизонтальными линиями.
- (квадрат 6) Проведите линию от первого круга к четвертому так, чтобы она проходила под кругом 2 и над кругом 3.
- (квадрат 7) Поставьте плюс в треугольнике, а цифру 1 в том месте, где треугольник и прямоугольник имеют общую площадь.
- (квадрат 8) Разделите второй круг на три, а четвертый на две части.
- (квадрат 10) Если сегодня не среда, то напишите предпоследнюю букву вашего имени.
- (квадрат 12) Поставьте в первый прямоугольник плюс, третий зачеркните, в шестом поставьте 0.
- (квадрат 13) Соедините точки прямой линией и поставьте плюс в меньшем треугольнике.
- (квадрат 15) Обведите кружком одну согласную букву и зачеркните гласные.
- (квадрат 17) Продлите боковые стороны трапеции до пересечения друг с другом и обозначьте точки пересечения последней буквой названия вашего города.
- (квадрат 18) Если в слове «синоним» шестая буква гласная, поставьте в прямоугольнике цифру 1.
- (квадрат 19) Обведите большую окружность и поставьте плюс в меньшую.
- (квадрат 20) Соедините между собой точки 2, 4, 5, миновав 1 и 3.
- (квадрат 21) Если два многозначных числа неодинаковы, поставьте галочку на линии между ними.
- (квадрат 22) Разделите первую линию на три части, вторую на две, а оба конца третьей соедините с точкой А.
- (квадрат 23) Соедините нижний конец первой линии с верхним концом второй, а верхний конец второй — с нижним концом четвертой.
- (квадрат 24) Зачеркните нечетные цифры и подчеркните четные.
- (квадрат 25) Заключите две фигуры в круг и отведите их друг от друга вертикальной линией.
- (квадрат 26) Под буквой А поставьте стрелку, направленную вниз, под буквой В — стрелку, направленную вверх, под буквой С — галочку.
- (квадрат 27) Если слова «дом» и «дуб» начинаются на одну и ту же букву, поставьте между ромбами минус.
- (квадрат 28) Поставьте в крайней слева клеточке 0, в крайней справа плюс, в середине проведите диагональ.
- (квадрат 29) Подчеркните снизу галочки, а в первую галочку впишите букву А.
- (квадрат 30) Если в слове «подарок» третья буква не И, напишите сумму чисел 3 + 5.
- (квадрат 31) В слове «салют» обведите кружком согласные буквы, а в слове дождь зачеркните гласные.
- (квадрат 32) Если число 54 делится на 9, опишите окружность вокруг четырехугольника.
- (квадрат 33) Проведите линию от цифры 1 к цифре 7, так, чтобы она проходила под четными цифрами и над нечетными.
- (квадрат 34) Зачеркните кружки без цифр, кружки с цифрами подчеркните.
- (квадрат 35) Под согласными буквами поставьте стрелку, направленную вниз, а под гласными — стрелку, направленную влево.
- (квадрат 36) Напишите слово «мир» так, чтобы первая буква была написана в круге, а вторая в прямоугольнике.
- (квадрат 37) Укажите стрелками направления горизонтальных линий вправо, а вертикальных вверх.
- (квадрат 39) Разделите вторую линию пополам и соедините оба конца первой линии с серединой второй.
- (квадрат 40) Отделите вертикальными линиями нечетные цифры от четных.
- (квадрат 41) Над линией поставьте стрелку, направленную вверх, а под линией — стрелку, направленную влево.
- (квадрат 42) Заключите букву М в квадрат, К в круг, О в треугольник.
- (квадрат 43) Сумму чисел 5 + 2 напишите в прямоугольнике, а разность этих же чисел — в ромб.
- (квадрат 44) Зачеркните цифры, делящиеся на 3, и подчеркните остальные.
- (квадрат 45) Поставьте галочку только в круг, а цифру 3 — только в прямоугольник).
- (квадрат 46) Подчеркните буквы и обведите кружками четные цифры.
- (квадрат 47) Поставьте нечетные цифры в квадратные скобки, а четные в круглые.



Перед проведением методики экспериментатор должен внимательно ознакомиться с заданиями и во время процедуры обследования четко произносить номер квадрата, в котором будет выполняться очередное задание, так как номера заданий и квадратов на бланке испытуемого не совпадают.
Оценка производится по количеству ошибок. Ошибкой считается любое пропущенное, не выполненное или выполненное с ошибкой задание.
Норма выполнения:
0-4 ошибки – высокая лабильность, хорошая способность к обучению;
5-9 ошибок – средняя лабильность;
10-14 ошибок – низкая лабильность, трудности в переобучении;
15 и более ошибок – мало успешен в любой деятельности.

Тест требует мало времени для проведения тестирования и обработки результатов, вместе с тем он дает достаточно точный прогноз профессиональной пригодности. Бланк ответов
Источник:
|
Открытие границ 2022
Обновлено 18 февраля 2022
Открытие границ 2022
Какие страны открыли границу, куда есть рейсы, можно ли уже покупать билеты, что надо знать заранее. Здесь мы, аналитический центр сервиса поездок и путешествий Туту.ру, собираем последние новости по ситуации с открытием границ. Информация постоянно обновляется.
Часто происходит так, что Россия
восстанавливает авиасообщение с той или иной страной, но
принимающая сторона россиян в качестве туристов не пускает.
Обращайте внимание не только на статусы открытого авиасообщения, но
и на полное описание по стране – там мы как раз рассказываем про
условия въезда.
Проверенные варианты
Больше стран
Закрыта
Авиасообщение восстановлено
Россиянам въезд разрешён
Закрыта
Россиянам въезд разрешён
Авиасообщение восстановлено
Россиянам въезд разрешён
Авиасообщение восстановлено
Авиасообщение восстановлено
Авиасообщение восстановлено
Авиасообщение восстановлено
Авиасообщение восстановлено
Авиасообщение восстановлено
Россиянам въезд разрешён
Россиянам въезд разрешён
Россиянам въезд разрешён
Авиасообщение восстановлено
Закрыт
Россиянам въезд разрешён
Авиасообщение восстановлено
Авиасообщение восстановлено
Авиасообщение восстановлено
Авиасообщение восстановлено
Россиянам въезд разрешён
Закрыта
Авиасообщение восстановлено
Россиянам въезд разрешён
Закрыт
Россиянам въезд разрешён
Закрыта
Авиасообщение восстановлено
Закрыта
Закрыт
Авиасообщение восстановлено
Авиасообщение восстановлено
Авиасообщение восстановлено
Авиасообщение восстановлено
Россиянам въезд разрешён
Россиянам въезд разрешён
Россиянам въезд разрешён
Авиасообщение восстановлено
Авиасообщение восстановлено
Россиянам въезд разрешён
Россиянам въезд разрешён
Закрыта
Авиасообщение восстановлено
Россиянам въезд разрешён
Авиасообщение восстановлено
Авиасообщение восстановлено
Авиасообщение восстановлено
Авиасообщение восстановлено
Авиасообщение восстановлено
Россиянам въезд разрешён
Россиянам въезд разрешён
Россиянам въезд разрешён
Закрыта
Россиянам въезд разрешён
Россиянам въезд разрешён
Авиасообщение восстановлено
Авиасообщение восстановлено
Россиянам въезд разрешён
Авиасообщение восстановлено
Россиянам въезд разрешён
Авиасообщение восстановлено
Авиасообщение восстановлено
Россиянам въезд разрешён
Россиянам въезд разрешён
Россиянам въезд разрешён
Россиянам въезд разрешён
Авиасообщение восстановлено
Авиасообщение восстановлено
Есть вопрос по поводу предстоящей поездки за границу? Можно задать его в чате путешественников
Присоединиться к чату
Что делать по возвращении в Россию?Всем возвращающимся из-за границы россиянам по прибытии нужно
сдать ПЦР-тест в течение трёх дней. До получения результатов теста
нужно соблюдать самоизоляцию по месту жительства
(пребывания). Результаты надо подгрузить на Госуслуги в
течение четырёх календарных дней с даты прибытия. В аэропортах в
Москве есть места, где можно сдать после прилёта. Всем приезжающим
на границе дают памятку-инструкцию, что конкретно делать.
До получения результатов теста
нужно соблюдать самоизоляцию по месту жительства
(пребывания). Результаты надо подгрузить на Госуслуги в
течение четырёх календарных дней с даты прибытия. В аэропортах в
Москве есть места, где можно сдать после прилёта. Всем приезжающим
на границе дают памятку-инструкцию, что конкретно делать.
Завершившим вакцинацию и переболевшим COVID-19 россиянам по возвращении в страну тесты сдавать не нужно. Данные о вакцинации или перенесённом заболевании указываются в анкете на сайте Госуслуг. Информация о том, что гражданин имеет сертификат о вакцинации или переболел COVID-19 в системе появляется автоматически (подтягивается из базы данных Минздрава). Сертификат переболевшего отобразится, только если заболевание официально диагностировали в медучреждении как COVID-19 (код МКБ-10 U07.1 и U07.2).
Вернувшимся из Кении, Ботсваны, ЮАР, Лесото, Намибии, Зимбабве,
Мозамбика, Мадагаскара, Эсватини, Танзании, Гонконга необходимо
пройти 14-дневный карантин и сдать дважды ПЦР-тест: в течение двух
дней со дня прибытия в РФ и с 10 по 12 день.
Добраться можно с пересадкой в стране, с которой Россия
возобновила авиасообщение. Например, через ОАЭ.
Список городов России, из которых сейчас разрешены международные
перелёты, можно посмотреть здесь.
Как лететь, если нет сертификата о вакцинации
Про QR-коды, сертификаты и остальное.
Читать новости в Телеграме
Медицинский центр Здоровый ребенок | Счастье там, где Здоровый ребенок!
О центре
Мечта каждой мамы — найти для своего ребенка врача, к которому можно обратиться за помощью в любое время. Он тут же откликнется, чтобы вместе с родителями разделить все заботы о здоровье их сына или дочери и дать единственно верный совет. Вы скажете, что таких докторов мало? Вы ошибаетесь. Такие доктора работают в медицинском центре «Здоровый ребёнок».
Ежедневно 7 дней в неделю, 365 дней в году медицинская служба нашей компании готова оказать лечебно-консультативные услуги по всем направлениям детских заболеваний.
Педиатрия. Детский доктор нашего центра — это врач, который отвечает за здоровье ребенка с первых дней жизни и до 18 лет. Специалисты нашего центра всегда объясняют свои действия, отвечают на вопросы родителей и не назначают лечение «на всякий случай» или ненужных диагностических исследований и анализов. Для наших маленьких пациентов работает служба помощи на дому во всех районах города: вызов педиатров, забор анализов, вакцинирование.
Неврология. Статистика показывает, что до 50% новорожденных детей получают диагноз «перинатальные патологии центральной нервной системы», потому что в это понятие врачи нередко включают и преходящие нарушения в функционировании центральной нервной системы. Мы знаем об этом, поэтому направление неврологии сегодня в нашем центре занимает ведущую роль.
Диагностика и лечение любой патологии нервной системы ребенка требует диагностического исследования. В своей работе мы используем:
- электроэнцефалографию;
- видео ЭЭГ-мониторинг;
- ультразвуковое исследование сосудов шеи и головы;
- нейросонографию.
Хирургия. Наша клиника располагает современным операционным блоком амбулаторной хирургии. Ожог, порез, травма — для наших врачей не проблема. Помимо экстренной помощи, мы предоставляем плановые консультации хирургов-ортопедов.
Особым спросом пользуется метод кинезиологического тейпирования. Это простая и эффективная технология лечения растяжения связок, мышечных болей, других травм, а также гематом и отеков с помощью специальной клейкой ленты (тейпа). Методика разработана японским рефлексотерапевтом Кензо Казе в 1970-х годах и уже более 20 лет применяется по всему миру, но в России стала известна совсем недавно.
Офтальмология. В медицинском центре «Здоровый ребёнок» работают врачи-офтальмологи, которые предоставляют возможность обследования зрения у детей с трехлетнего возраста. Проводится полная диагностика, составляется медицинский прогноз состояния зрения и программа профилактики зрения. Индивидуальная программа лечения формируется для каждого пациента с учетом не только состояния, но и возраста, характера, образа жизни. Такой комплексный подход в нашей клинике считается нормой.
Проводится полная диагностика, составляется медицинский прогноз состояния зрения и программа профилактики зрения. Индивидуальная программа лечения формируется для каждого пациента с учетом не только состояния, но и возраста, характера, образа жизни. Такой комплексный подход в нашей клинике считается нормой.
Функциональная диагностика. Лабораторная служба медицинского центра «Здоровый ребёнок» осуществляет более 1500 анализов разного спектра, причем материал для них можно сдать в одном месте.
Кроме того, в отделении функциональной диагностики можно сделать:
- ультразвуковые исследования;
- холтер-мониторинг;
- спирографию;
- электрокардиографию.
Помощь специалистов. Если у ребенка при первичном осмотре выявляется специфическая патология и требуется помощь узкого специалиста, мы предлагаем услуги нужных врачей этого отделения. Команда включает в себя эндокринолога, гастроэнтеролога, пульмонолога и аллерголога.
Болят суставы? Исследования на артроз и артрит
Важно помнить! Информацию из данного раздела нельзя использовать для самодиагностики и самолечения. В случае боли или иного обострения заболевания диагностические исследования должен назначать только лечащий врач. Для постановки диагноза и правильного назначения лечения следует обращаться к Вашему лечащему врачу.
Начало заболевания характеризуется болью в суставах, когда крутит руку или ногу. Все чаще по утрам беспокоит скованность движений, которая может длиться несколько часов. Клиническая картина добавляется отеками и покраснениями в районе суставов. Через некоторое время становится невозможно совершать самые простые действия — ходить, шевелить пальцами и другими частями тела, где начало развиваться заболевание. И в зависимости от особенностей протекания болезни и иных факторов называют это заболевание артритом или артрозом.
Артрит
Причиной артрита является перенесенная инфекция, «сбой» иммунной системы организма или нарушение обмена веществ. Способствуют болезни наследственная предрасположенность и «сидячий» образ жизни. Как правило, артритом заболевают люди до 40 лет. Хотя бывают и исключения, когда уже в достаточно пожилом возрасте болезнь может проявиться после перенесенной простуды или иного инфекционного заболевания.
Способствуют болезни наследственная предрасположенность и «сидячий» образ жизни. Как правило, артритом заболевают люди до 40 лет. Хотя бывают и исключения, когда уже в достаточно пожилом возрасте болезнь может проявиться после перенесенной простуды или иного инфекционного заболевания.
Чаще всего в практике лечения этого заболевания встречается ревматоидный артрит, который поражает соединительные ткани и мелкие суставы. Ревматоидный артрит относится к классу аутоиммунных заболеваний. Здоровый организм вырабатывает защитные антитела для уничтожения вирусов, бактерий. Но, по неизвестным на сегодняшний день причинам, эти антитела могут нападать на здоровые клетки суставов, тем самым разрушая их. Врачи полагают, что причинами такого поведению антител являются наследственные признаки организма, вирусы и стрессы. При ревматоидном артрите суставы начинают деформироваться, возникают отеки и покраснения в области суставов, небольшие уплотнения (ревматоидные узелки). После пробуждения, когда тело долгое время находилось в неподвижности, появляется скованность и боли в суставах. Одновременно увеличивается температура и появляется общая слабость. Коварство болезни заключается в том, что помимо суставов постепенно поражаются кожа, сердце, легкие, почки и печень. Иногда наступают периоды временного улучшения, но затем заболевание прогрессирует с большей силой, поэтому необходимо оперативное и длительное лечение.
Одновременно увеличивается температура и появляется общая слабость. Коварство болезни заключается в том, что помимо суставов постепенно поражаются кожа, сердце, легкие, почки и печень. Иногда наступают периоды временного улучшения, но затем заболевание прогрессирует с большей силой, поэтому необходимо оперативное и длительное лечение.
Артроз
Людей старше сорока лет чаще всего подвержены риску заболевания артрозом. Происходит разрушение суставов и изменение костной ткани. Заболеванию могут способствовать перенесенные травмы, неправильное питание (злоупотребление жареной и жирной пищей), избыточный вес, малоподвижный образ жизни, генетическая предрасположенность, а также врожденные дефекты сустава. Чаще артроз развивается под воздействием длительного стресса. Во время стресса происходит спазм мышц, и в результате мышечного давления хрящ сустава начинает разрушаться. Кроме того, в данном процессе свою роль играют и гормоны стресса, в частности кортизол, который накапливаясь и нарушая кровообращение вокруг сустава, разрушает хрящевую ткань. Симптомы артроза: резкие суставные боли, усиливающиеся к вечеру, опухоль отдельных суставов (в первую очередь пальцев ног), ограниченная подвижность.
Симптомы артроза: резкие суставные боли, усиливающиеся к вечеру, опухоль отдельных суставов (в первую очередь пальцев ног), ограниченная подвижность.
При первых недомоганиях, о которых идет речь, необходимо обратиться к врачу. Чем раньше будет поставлен диагноз и назначена терапия, тем выше шанс предотвратить осложнения и быстро «встать на ноги».
Исследования на артроз и артрит включают в себя следующие анализы:
- общий анализ крови — определяется количество эритроцитов, лейкоцитов, тромбоцитов, гемоглобина в крови для диагностики воспалительного процесса;
- скорость оседания эритроцитов — показывает активность воспалительного процесса в организме;
- ревматоидный фактор — диагностика аутоиммунных заболеваний;
- C-реактивный белок — диагностика воспаления и повреждения тканей;
- другие анализы, с помощью которых можно диагностировать заболевание на самых ранних стадиях в зависимости от показанного случая.
 youtube.com/embed/GHPdmcDOQ84″ frameborder=»0″ allowfullscreen=»allowfullscreen»/>
youtube.com/embed/GHPdmcDOQ84″ frameborder=»0″ allowfullscreen=»allowfullscreen»/>Где сдать анализ при болях в суставах.
Сдать анализ крови артрит или артроз можно в любом пункте Синэво в Минске, Гомеле, Бресте, Гродно, Витебске, Могилеве, Бобруйске, Барановичах, Солигорске, Слуцке, Полоцке, Новополоцке, Орше, Жлобине, Светлогорске, Молодечно, Пинске, Борисове, Речице, Мозыре, Сморгони.
Все исследования можно пройти в лаборатории «Синэво». Воспользуйтесь полным обследованием при болях в суставах — пакет 10.1 «Ревматологическое первичное обследование» или пакет 10.2 «Ревматологическое расширенное обследование».
Will или going to?
Что выбрать, will или going to? Этот вопрос часто встает перед теми, кто изучает английский язык. Чтобы понять разницу между will и going to, нужно разобраться, в каких случаях они употребляются — отдельно и в сравнении.
Где употребляется willОсновная функция глагола will — построение будущего времени (Future Simple). Он выполняет чисто техническую, вспомогательную функцию, не добавляя в предложение отдельного смысла или эмоционального оттенка.
Он выполняет чисто техническую, вспомогательную функцию, не добавляя в предложение отдельного смысла или эмоционального оттенка.
- Простые действия и факты в будущем
I’ll be home in the evening. — Я буду дома вечером.
- Повторяющиеся действия в будущем
In autumn I will go to school every day. — Осенью я буду ходить в школу каждый день.
- Последовательные действия в будущем
Tomorrow I will go to the library and borrow some books. — Завтра я пойду в библиотеку и возьму книги.
- Прогнозы относительно будущего, основанные на личном мнении, ожиданиях, надеждах и т.д.
I think I’ll be rich one day. — Думаю, когда-нибудь я разбогатею.
- Спонтанные решения и действия
— Are you ready to order? — Yes, I will take a sandwich and a coffee.
— Вы готовы заказывать? — Да, я возьму сэндвич и кофе.
I will always be with you. — Я всегда буду с тобой.
Don’t move or I’ll kill you! — Не двигайся или я тебя убью!
- Предостережения
Don’t touch the kettle, it’s hot! You’ll burn yourself! — Не прикасайся к чайнику, он горячий! Ты обожжешься!
Will you help me? — Вы мне поможете?
- Действия, которые неизбежно произойдут, на которые невозможно повлиять
It will rain tomorrow. — Завтра пойдет дождь.
Теперь следует рассмотреть случаи употребления going to, чтобы научиться выбирать will или going to для правильного построения предложения.
Где употребляется to be going toGoing to — конструкция, которая используется для выражения планов, намерений, прогнозов на будущее.
I am going to buy a new camera. — Я собираюсь купить новую камеру.
He is going to publish his new book next year. — Он собирается опубликовать свою новую книгу в следующем году.
The scientists are going to launch a new space project soon. — Ученые вскоре планируют запустить новую космическую программу.
Случаи употребления Going to- Запланированные действия
— What are you going to do on your holiday? — I am going to visit my parents and spend some time in the countryside.
— Что ты собираешься делать в отпуске? — Я собираюсь навестить родителей и провести несколько дней за городом.
- Решения и намерения
Jim and Mary are going to get married. — Джим и Мэри собираются (решили) пожениться.
- Прогнозы, основанные на фактах
It is going to rain. — Cейчас пойдет дождь.
You are not going to wear this dress! — Ты не наденешь это платье!
I am not going to do your work! You get paid for it! — Я не собираюсь выполнять твою работу! Тебе за нее платят!
Will и going to — разницаНа предмет выражения будущего действия с помощью will и going to существует несколько стереотипов, которые прочно засели в голове у многих, кто изучает английский язык.
Стереотип номер один: любое будущее действие — это will. Стереотип номер два: у выражения going to есть только одно значение — «собираться что-то сделать». В следовании данным стереотипам присутствует определенная логика, но это не поможет точно выразить свою мысль на английском языке.
Will или going to — сложные случаи- Решение. Will указывает на то, что решение спонтанное, то есть говорящий не задумывался над этим решением заранее.
— Any plans for the weekend? — I have not decided yet. I think I will visit my parents.
— Есть планы на выходные? — Я еще не решил. Думаю, я навещу родителей.
В этой ситуации понятно, что решение по поводу планов на выходные принимается в момент речи, и говорящий до этого не думал над ним.
— Billy, who do you want to be in the future? — Hmm, I think I will become a doctor!
— Билли, кем ты хочешь стать в будущем? — Хм, думаю, я стану доктором!
Это спонтанный ответ, какой обычно дают дети на подобные вопросы.
- Просьбы, обещания, угрозы, предупреждения тоже передаются при помощи will, потому что чаще всего высказываются спонтанно. Если же решение обдумано заранее, до разговора, то оно уже переходит в разряд планов, поэтому использовать следует going to.
— Any plans for the weekend? — Yes, I am going to visit my parents.
— Есть планы на выходные? — Я собираюсь (планирую) навестить родителей.
Используя going to, говорящий показывает, что он уже все обдумал и запланировал.
— Billy, who do you want to be in the future? — I am going to be a doctor. Biology is my favourite subject.
— Билли, кем ты хочешь стать в будущем? — Я планирую стать доктором. Биология – мой любимый предмет.
Этот ответ подразумевает, что ребенок уже думал над этим, решение взвешенное и больше похоже на план.
-
Прогноз. Future Simple используется, когда мы высказываем свой прогноз по поводу будущего действия, основываясь на собственных соображениях, ожиданиях.

В данном контексте will используется с
глаголами:
- think (думать)
- believe (считать)
- doubt (сомневаться)
- expect (ожидать)
- hope (надеяться)
наречиями:
- probably (вероятно)
- maybe (может быть)
- certainly (безусловно)
- perhaps (возможно)
фразами:
- I’m sure… — Я уверен…
- I’m certain… — Я убежден…
- There is no doubt… — Несомненно…
- I’m afraid… — Боюсь, что…
I think I will be rich one day if I work hard. — Я думаю, однажды я разбогатею, если буду усердно работать.
Так может сказать человек, у которого на данный момент, в принципе, нет предпосылок для получения богатства, но он чувствует, что у него это может получиться.
I am sure he won’t get the job. To my mind, he is not clever enough. — Я уверен, он не получит эту работу. На мой взгляд, он недостаточно умен.
— Я уверен, он не получит эту работу. На мой взгляд, он недостаточно умен.
Это личное мнение говорящего, работодатель может подумать иначе. То есть данный прогноз является субъективным.
Однако, если в начале предложения стоит глагол, наречие или фраза из вышеприведенного списка, это еще не гарантирует, что за ними обязательно должен следовать will и Future Simple. При выборе средств выражения будущего времени следует обращать внимание на контекст, на ситуацию.
- Если есть конкретное, видимое подтверждение того, что действие произойдет, то, чтобы передать это, использовать следует going to.
I think I am going to be rich! The share price is on the rise. — Думаю, я скоро разбогатею! Курс акций растет.
В приведенной выше ситуации у говорящего, скорее всего, есть видимое подтверждение того, что его состояние в скором времени увеличится, что и позволяет ему с уверенностью сделать такой прогноз.
I am sure, he is not going to get the job. He doesn’t have enough experience. — Я уверен, он не получит эту работу. У него недостаточно опыта.
He doesn’t have enough experience. — Я уверен, он не получит эту работу. У него недостаточно опыта.
В данной ситуации говорящий знает наверняка (или практически наверняка), что шансов у кандидата мало из-за недостатка опыта.
- Если что-то вот-вот произойдет, когда имеется видимое доказательство того, что действие совершится, то выразить его лучше при помощи going to, а не will. Обычно внимание собеседника к таким действиям привлекают словами: «Look!», «Listen!», «Be careful!» или другими, которые указывают на то, что неминуемо что-то случится в ближайшем будущем.
Look! He is standing on the edge of the cliff, he is going to fall! — Смотри! Он стоит на краю утеса, он сейчас упадет!
Look at the sky, I think it is going to rain. — Посмотри на небо, я думаю, будет дождь.
- И еще один момент, который нужно принимать во внимание: will чаще используется для выражения предположений о более далеком будущем.
Надеемся, эта статья была полезной, и теперь вы яснее видите разницу между will и going to. Желаем успехов!
Желаем успехов!
Новости
11.02.2022
QR-код по тесту на антитела
С 21 февраля на портале Госуслуг можно будет получить QR-код на основании справки о наличии антител IgG к коронавирусу.
04.02.2022
ImmunoCAP – можно не натощак!
Приходите на анализы ImmunoCAP в любое время, когда вам удобно, – теперь эти анализы можно сдавать независимо от приема пищи.
24.01.2022
Прогноз и мониторинг эффективности АСИТ
Эксклюзивный тест для мониторинга эффективности АСИТ – только в СИТИЛАБ! АСИТ (аллерген-специфическая иммунотерапия) – единственный на сегодняшний день метод, который предотвращает симптомы аллергии, а не купирует их.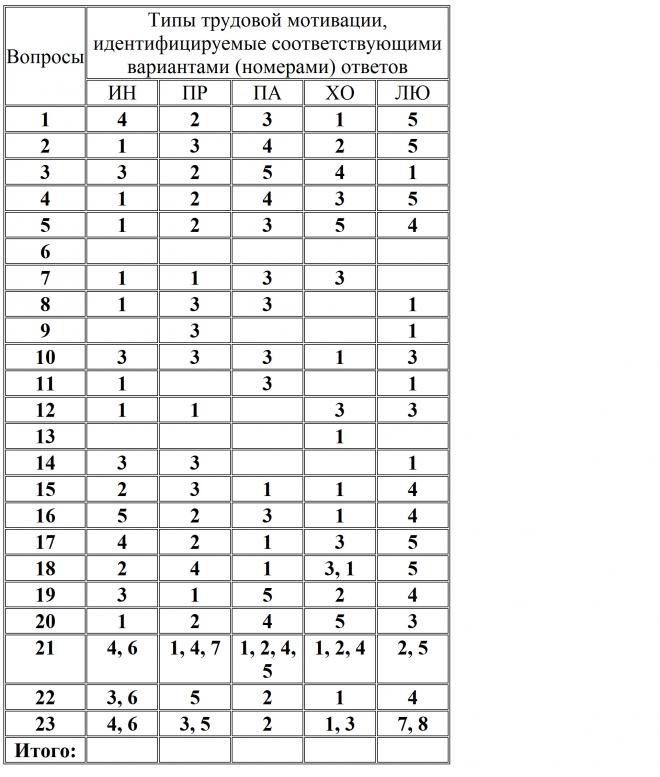
20.01.2022
Экспресс-тест на COVID-19 за 2 часа!
Быстрее, проще, точнее! Срочный тест на COVID-19 в СИТИЛАБ – полноценное высокоточное лабораторное исследование со скоростью аптечного экспресс-теста. Сертификат действителен в России и за рубежом.
10.01.2022
Эксклюзивные исследования СИТИЛАБ в урологической практике
В спектре СИТИЛАБ представлен уникальный биоматериал – концентрированный осадок эякулята, значительно повышающий выявляемость инфекционных патогенов, а также это единственный биоматериал для диагностики семенных инфекций ВПЧ у мужчин.
22. 12.2021
12.2021
Вакцинация в Сербии для граждан РФ!
Хотите привиться европейской вакциной? Подготовьтесь к вакцинации в СИТИЛАБ.
«Ситилаб Сербия» помогает пациентам организовать процесс вакцинации в Белграде бесплатно при предоставлении тестов «Ситилаб Россия».
09.12.2021
ПЦР-тест на COVID-19 для путешествий
Уже решили, как проведете праздники и новогодние каникулы? Может быть, собираетесь в путешествие? Или хотите навестить родственников? Сдайте быстрый и надежный ПЦР-тест на коронавирус в СИТИЛАБ.
09.12.2021
Тестирование на омикрон-штамм
«Омикрон» — новый штамм коронавируса, который впервые обнаружили совсем недавно, в ноябре этого года, в ЮАР. Он уже успел насторожить и врачей, и пациентов. Что известно о мутации вируса на данный момент? И самое главное, способны ли современные ПЦР-тесты обнаружить «омикрон»?
Он уже успел насторожить и врачей, и пациентов. Что известно о мутации вируса на данный момент? И самое главное, способны ли современные ПЦР-тесты обнаружить «омикрон»?
Получение онлайн-прогнозов | Прогноз платформы ИИ | Облако Google
AI Platform Prediction онлайн-прогнозирование — это сервис, оптимизированный для работы с вашими данными. через размещенные модели с минимально возможной задержкой. Вы отправляете небольшие партии данных в сервис, и он возвращает ваши прогнозы в ответ.
Узнать о онлайн против пакетного прогнозирования или прочитать обзор концепций прогнозирования.
Прежде чем начать
Чтобы запросить прогнозы, вы должны сначала:
регионов
Онлайн-прогнозирование доступно в некоторых регионах. Тем более машина разная
типы доступны в каждом
область, край. Чтобы узнать о наличии онлайн-прогноза в каждом регионе,
читайте путеводитель по регионам.
Тем более машина разная
типы доступны в каждом
область, край. Чтобы узнать о наличии онлайн-прогноза в каждом регионе,
читайте путеводитель по регионам.
Создание моделей и версий
Вы принимаете следующие важные решения о том, как выполнять онлайн-прогнозирование. при создании модели и ресурсов версии:
| Ресурс создан | Решение, указанное при создании ресурса |
|---|---|
| Модель | Регион, в котором выполняются прогнозы |
| Модель | Включить ведение журнала онлайн-прогнозов |
| Версия | Версия среды выполнения для использования |
| Версия | Версия Python для использования |
| Версия | Тип машины для онлайн-предсказания |
После первоначального создания
модель или версия.Если вам нужно изменить эти настройки, создайте новую модель или
ресурс версии с новыми настройками и повторно разверните модель.
Типы машин, доступные для онлайн-прогноза
При создании версии можно выбрать тип виртуальной машины AI Platform Prediction использует узлы онлайн-прогнозирования. Узнать больше о машине типы.
Запрос журналов для запросов онлайн-прогноза
Служба прогнозирования AI Platform Prediction не предоставляет зарегистрированные информация о запросах по умолчанию, потому что журналы несут расходы.онлайн предсказание при высокой частоте запросов в секунду (QPS) может привести к значительным количество журналов, которые подлежат Cloud Logging ценообразование или BigQuery ценообразование.
Если вы хотите включить ведение журнала онлайн-прогнозов, вы должны настроить его при создать модель ресурс или когда вы создать версию модели ресурс в зависимости от какой тип ведения журнала вы хотите включить. Существует три типа регистрации, которые вы можете включить самостоятельно:
Журнал доступа , который регистрирует такую информацию, как метка времени и задержка для каждого запрос в Cloud Logging.
Вы можете включить ведение журнала доступа при создании ресурса модели.
Ведение журнала консоли , в котором регистрируются потоки
stderrиstdoutиз вашего узлы прогнозирования для облачного ведения журналов и могут быть полезны для отладки. Этот тип ведения журнала находится в предварительной версии для типов машин Compute Engine (N1) и обычно доступен для устаревшие (MLS1) типы машин.Вы можете включить ведение журнала консоли при создании ресурса модели.
Регистрация запроса-ответа , в которой регистрируется образец онлайн-прогноза. запросы и ответы к таблице BigQuery.Этот тип ведение журнала находится в стадии бета-тестирования.
Вы можете включить ведение журнала запросов и ответов, создав ресурс версии модели, затем обновить это версия.
Примечание. Не включайте ведение журнала запросов и ответов, если вы планируете настроить непрерывную оценка версии вашей модели. Непрерывная оценка автоматически настраивает ведение журнала запросов и ответов.

gcloud
Чтобы включить ведение журнала доступа , включите флаг --enable-logging , когда вы
создайте свою модель с помощью моделей ИИ-платформы gcloud создают команда.Например:
модели gcloud ai-platform создают MODEL_NAME \
--region=us-central1 \
--включить ведение журнала
Чтобы включить ведение журнала консоли (предварительная версия), используйте компонент gcloud beta и
включите флаг --enable-console-logging . Например:
Компоненты gcloud устанавливают бета-версию
Модели gcloud beta ai-platform создают MODEL_NAME \
--region=us-central1 \
--enable-консоль-логгирование
В настоящее время вы не можете включить ведение журнала запросов-ответов (бета-версия) с помощью gcloud интерфейс командной строки. Вы можете включить этот тип регистрации только при отправке
Вы можете включить этот тип регистрации только при отправке проекты.модели.версии.патч запрос к REST API.
REST API
Чтобы включить ведение журнала доступа , установите для onlinePredictionLogging значение True в
Ресурс модели при создании модели с помощью проектов.моделей.создать .
Чтобы включить ведение журнала консоли (бета), установите поле onlinePredictionConsoleLogging на True в ресурсе модели.
Регистрация запроса-ответа
В отличие от других типов ведения журнала, вы не можете включить ведение журнала «запрос-ответ».
при создании модели. Вместо этого вы можете включить его с помощью проекты. метод на существующей версии модели. (Сначала необходимо создать модель
версия с использованием
Google Cloud Console, интерфейс командной строки  модели.версии.патч
модели.версии.патч gcloud или REST API.)
Чтобы включить ведение журнала запросов и ответов, заполните requestLoggingConfig .
поле версии
ресурс
со следующими записями:
-
samplePercentage: число от 0 до 1, определяющее долю запросы на регистрацию.Например, установите это значение на1, чтобы регистрировать все запросы или на0.1для регистрации 10% запросов. bigqueryTableName: полное имя ( PROJECT_ID . DATASET_NAME . TABLE_NAME ) из таблицу BigQuery, в которой вы хотите регистрировать запросы и ответы. Таблица должна уже существовать со следующим
схема:Имя поля Тип Режим Модель STRING НЕОБХОДИМЫЕ model_version STRING НЕОБХОДИМЫЕ раз TIMESTAMP НЕОБХОДИМЫЕ RAW_DATA строки требуется RAW_PREDICTICT String NULLBLABLE Snaltruth String NULLBLABLE Узнайте, как создать меры стол.
 Таблица должна уже существовать со следующим
схема:
Таблица должна уже существовать со следующим
схема: Вы можете использовать инструмент «что, если» (WIT)
в средах ноутбуков для проверки моделей прогнозирования платформы AI с помощью
интерактивная панель. Инструмент «Что, если» интегрируется с TensorBoard, Jupyter.
блокноты, блокноты Colab и JupyterHub. Он также предустановлен на
Вершина AI Workbench
блокноты, управляемые пользователями
Экземпляры TensorFlow.
Узнать как использовать инструмент «что, если» с платформой ИИ.
Форматирование ввода для онлайн-прогноза
Форматирование экземпляров как строк JSON
Основной формат онлайн-прогноза — список экземпляров данных.Они могут быть либо простыми списками значений, либо членами объекта JSON, в зависимости от того, как вы настроили входные данные в своем учебном приложении. Модели TensorFlow и пользовательские процедуры прогнозирования могут принимать более сложные входные данные, в то время как большинство моделей scikit-learn и XGBoost ожидают список чисел в качестве входных данных.
В этом примере показан входной тензор и ключ экземпляра для модели TensorFlow:
{"значения": [1, 2, 3, 4], "ключ": 1}
Структура строки JSON может быть сложной, если она соответствует следующим правилам:
Верхний уровень данных экземпляра должен быть объектом JSON: словарь пары ключ/значение.
Отдельные значения в экземпляре объекта могут быть строками, числами или списками. Вы не можете встраивать объекты JSON.
Списки должны содержать только элементы одного типа (включая другие списки). Ты нельзя смешивать строковые и числовые значения.
Вы передаете входные экземпляры для онлайн-прогноза в качестве тела сообщения для проектов.предсказать вызов . Подробнее о форматировании тела запроса
требования.
gcloud
Вы можете отформатировать ввод двумя разными способами, в зависимости от того, как вы планируете
чтобы отправить запрос прогноза.Мы рекомендуем вам использовать gcloud AI-платформа прогнозирует флаг команды --json-request . В качестве альтернативы вы можете использовать --json-instances флаг с данными JSON, разделенными новой строкой.
Для —json-request
Сделайте каждый экземпляр элементом в массиве JSON и предоставьте массив как экземпляров полей файла JSON. Например:
instances.json
{"экземпляры": [
{"значения": [1, 2, 3, 4], "ключ": 1},
{"значения": [5, 6, 7, 8], "ключ": 2}
]}
Для —json-instances
Убедитесь, что ваш входной файл представляет собой файл JSON с разделителями новой строки, каждый instance как объект JSON, по одному экземпляру в строке.Например:
экземпляров.jsonl
{"значения": [1, 2, 3, 4], "ключ": 1}
{"значения": [5, 6, 7, 8], "ключ": 2}
REST API
Сделайте каждый экземпляр элементом в массиве JSON и предоставьте массив как экземпляров полей объекта JSON. Например:
Например:
{"экземпляры": [
{"значения": [1, 2, 3, 4], "ключ": 1},
{"значения": [5, 6, 7, 8], "ключ": 2}
]}
Двоичные данные на входе предсказания
Примечание: Этот следующий раздел относится только к прогнозированию с помощью TensorFlow.Двоичные данные не могут быть отформатированы как строки в кодировке UTF-8, поддерживаемые JSON. Если у вас есть двоичные данные во входных данных, вы должны использовать кодировку base64 для представлять его. Требуется следующее специальное форматирование:
Ваша закодированная строка должна быть отформатирована как объект JSON с одним ключом названный
b64. В следующем примере Python 2.7 кодируется буфер необработанных файлов JPEG. данные с использованием библиотеки base64 для создания экземпляра:{"image_bytes": {"b64": base64. b64encode(jpeg_data)}}
В Python 3 кодировка base64 выводит последовательность байтов. Вы должны преобразовать это в строку, чтобы сделать ее сериализуемой JSON:
{'image_bytes': {'b64': base64.b64encode(jpeg_data).decode()}}В коде вашей модели TensorFlow вы должны назвать псевдонимы для вашего двоичного файла входные и выходные тензоры, чтобы они заканчивались на «_bytes».
 b64encode(jpeg_data)}}
b64encode(jpeg_data)}}
Запрос прогнозов
Запросите онлайн-прогноз, отправив экземпляры входных данных в виде JSON. строка в прогнозировать запрос.Для форматирование тела запроса и ответа, см. детали запроса прогноза.
Если вы не укажете версию модели, ваш запрос прогноза использует версия модели по умолчанию.
gcloud
Создайте переменные среды для хранения параметров, включая версию значение, если вы решили указать конкретную версию модели:
MODEL_NAME="[ВАШЕ-ИМЯ-МОДЕЛИ]" INPUT_DATA_FILE="instances. json"
ИМЯ_ВЕРСИИ="[ИМЯ-ВАШЕЙ-ВЕРСИИ]"
Использование gcloud ai-платформа прогнозирует отправлять экземпляры в развернутую модель.Обратите внимание, что
--versionявляется необязательным.gcloud AI-платформа прогнозирует \ --model=$ИМЯ_МОДЕЛИ \ --version=$ИМЯ_ВЕРСИИ \ --json-request=$INPUT_DATA_FILE \ --region= РЕГИОНЗаменить РЕГИОН на регион регионального конечная точка, где вы создали свой модель. если ты создал свою модель на глобальной конечной точке, опустите флаг
--region.Инструмент gcloud анализирует ответ и выводит прогнозы на ваш терминал в удобочитаемом формате.Вы можете указать другой вывод формат, такой как JSON или CSV, используя флаг —format с вашим предсказать команду. См. доступные выходные форматы.
 json"
ИМЯ_ВЕРСИИ="[ИМЯ-ВАШЕЙ-ВЕРСИИ]"
json"
ИМЯ_ВЕРСИИ="[ИМЯ-ВАШЕЙ-ВЕРСИИ]"
Python
Вы можете использовать Клиентская библиотека Google API для Python для вызова AI Platform Training and Prediction API без ручного создания HTTP Запросы. Перед запуском следующего примера кода необходимо настроить аутентификация.
Как настроить аутентификацию
Чтобы настроить аутентификацию, вам необходимо создать ключ учетной записи службы и установить среду переменная для пути файла к ключу учетной записи службы.
Создайте учетную запись службы:
В Cloud Console перейдите на страницу Создать сервисный аккаунт .
Перейти к созданию сервисного аккаунта
- В поле Имя учетной записи службы введите имя.
- Необязательно: В поле Описание учетной записи службы введите описание.
- Нажмите Создать .
- Щелкните поле Выберите роль . В разделе Все роли выберите AI Platform > AI Platform Admin .
- Щелкните Добавить еще одну роль .
Щелкните поле Выберите роль . В разделе Все роли выберите Хранилище > Администратор объекта хранения .
Примечание . Выбранные вами роли позволяют вашей учетной записи службы получать доступ к ресурсам.Ты сможешь просмотреть и изменить эти роли позже с помощью Облачная консоль. Если вы разрабатываете производство приложение, вам может потребоваться указать роли с меньшим количеством разрешений, чем администратор платформы AI и Администратор объекта хранения. Для получения дополнительной информации см. контроль доступа для Прогноз платформы ИИ.Щелкните Готово , чтобы создать учетную запись службы.
Не закрывайте окно браузера.Вы будете использовать его на следующем шаге.
Создайте ключ сервисной учетной записи для аутентификации:
- В Cloud Console щелкните адрес электронной почты учетной записи службы, которую вы созданный.
- Нажмите Ключи .
- Нажмите Добавить ключ , затем Создайте новый ключ .
- Нажмите Создать . Файл ключа JSON загружается на ваш компьютер.
- Нажмите Закрыть .
Установите переменную среды GOOGLE_APPLICATION_CREDENTIALS на путь к файлу JSON, который содержит ключ вашей учетной записи службы. Эта переменная применяется только к вашему текущему сеансу оболочки, поэтому, если вы откроете новый сеанс, установите переменную снова.
Пример: Linux или macOS
Замените [PATH] на путь к файлу JSON, который содержит ключ вашей сервисной учетной записи.
экспорт GOOGLE_APPLICATION_CREDENTIALS="[ПУТЬ]"
Например:
экспорт GOOGLE_APPLICATION_CREDENTIALS="/home/user/Downloads/service-account-file.json"
Пример: Windows
Замените [PATH] на путь к файлу JSON, который содержит ключ вашей служебной учетной записи, а [FILE_NAME] с имя файла.
С PowerShell:
$env:GOOGLE_APPLICATION_CREDENTIALS="[ПУТЬ]"
Например:
$env:GOOGLE_APPLICATION_CREDENTIALS="C:\Users\username\Downloads\[FILE_NAME].
json" С командной строкой:
установить GOOGLE_APPLICATION_CREDENTIALS=[ПУТЬ]


 json"
json" Java
Вы можете использовать Клиентская библиотека API Google для Java для вызова AI Platform Training and Prediction API без ручного создания HTTP Запросы.Перед запуском следующего примера кода необходимо настроить аутентификацию.
Как настроить аутентификацию
Чтобы настроить аутентификацию, вам необходимо создать ключ учетной записи службы и установить среду переменная для пути файла к ключу учетной записи службы.
Создайте учетную запись службы:
В Cloud Console перейдите на страницу Создать сервисный аккаунт .
Перейти к созданию сервисного аккаунта
- В поле Имя учетной записи службы введите имя.
- Необязательно: В поле Описание учетной записи службы введите описание.
- Нажмите Создать .
- Щелкните поле Выберите роль . В разделе Все роли выберите AI Platform > AI Platform Admin .
- Щелкните Добавить еще одну роль .
Щелкните поле Выберите роль . В разделе Все роли выберите Хранилище > Администратор объекта хранения .
Примечание . Выбранные вами роли позволяют вашей учетной записи службы получать доступ к ресурсам. Ты сможешь просмотреть и изменить эти роли позже с помощью Облачная консоль. Если вы разрабатываете производство приложение, вам может потребоваться указать роли с меньшим количеством разрешений, чем администратор платформы AI и Администратор объекта хранения. Для получения дополнительной информации см.
контроль доступа для
Прогноз платформы ИИ.Щелкните Готово , чтобы создать учетную запись службы.
Не закрывайте окно браузера. Вы будете использовать его на следующем шаге.
Создайте ключ сервисной учетной записи для аутентификации:
- В Cloud Console щелкните адрес электронной почты учетной записи службы, которую вы созданный.
- Нажмите Ключи .
- Нажмите Добавить ключ , затем Создайте новый ключ .
- Нажмите Создать .Файл ключа JSON загружается на ваш компьютер.
- Нажмите Закрыть .
Установите переменную среды GOOGLE_APPLICATION_CREDENTIALS на путь к файлу JSON, который содержит ключ вашей учетной записи службы.
Эта переменная применяется только к вашему текущему сеансу оболочки, поэтому, если вы откроете
новый сеанс, установите переменную снова.Пример: Linux или macOS
Замените [PATH] на путь к файлу JSON, который содержит ключ вашей сервисной учетной записи.
экспорт GOOGLE_APPLICATION_CREDENTIALS="[ПУТЬ]"
Например:
экспорт GOOGLE_APPLICATION_CREDENTIALS="/home/user/Downloads/service-account-file.json"
Пример: Windows
Замените [PATH] на путь к файлу JSON, который содержит ключ вашей служебной учетной записи, а [FILE_NAME] с имя файла.
С PowerShell:
$env:GOOGLE_APPLICATION_CREDENTIALS="[ПУТЬ]"
Например:
$env:GOOGLE_APPLICATION_CREDENTIALS="C:\Users\username\Downloads\[FILE_NAME].
json" С командной строкой:
установить GOOGLE_APPLICATION_CREDENTIALS=[ПУТЬ]

 Для получения дополнительной информации см.
контроль доступа для
Прогноз платформы ИИ.
Для получения дополнительной информации см.
контроль доступа для
Прогноз платформы ИИ. Эта переменная применяется только к вашему текущему сеансу оболочки, поэтому, если вы откроете
новый сеанс, установите переменную снова.
Эта переменная применяется только к вашему текущему сеансу оболочки, поэтому, если вы откроете
новый сеанс, установите переменную снова. json"
json" Устранение неполадок онлайн-прогноза
Общие ошибки в онлайн-прогнозировании включают следующее:
- Ошибки нехватки памяти
- Входные данные имеют неверный формат
- Один запрос онлайн-прогноза должен содержать не более 1.5 МБ данных.
Запросы, созданные с помощью интерфейса командной строки
gcloud, могут обрабатывать не более 100 экземпляров на файл. Чтобы получить прогнозы для большего количества экземпляров одновременно, использовать пакетное предсказание.
Попробуйте уменьшить модель
размер до
развертывание его в AI Platform Prediction для прогнозирования.
Подробнее см. устранение неполадок онлайн-прогнозирования.
Что дальше
онлайн-прогнозов | Таблицы AutoML | Облако Google
Бета
На этот продукт распространяются Условия предложений Pre-GA.
Условия использования Google Cloud.Продукты Pre-GA могут иметь ограниченную поддержку,
и изменения в продуктах до GA могут быть несовместимы с другими версиями до GA. Для получения дополнительной информации см.
описания этапов запуска.
Для получения дополнительной информации см.
описания этапов запуска.
На этой странице описывается, как получать онлайн-прогнозы (одиночные, с малой задержкой) из Таблицы AutoML.
Введение
После того, как вы создали (обучили) модель, вы можете развернуть модель и запросить онлайн (в режиме реального времени) предсказания. Онлайн-прогнозы принимают одну строку данных и предоставляют прогнозируемый результат на основе на вашей модели для этих данных.Вы используете онлайн-прогнозы, когда вам нужно предсказание в качестве входных данных для вашего потока бизнес-логики.
Прежде чем вы сможете запросить онлайн-прогноз, вы должны развернуть свою модель. За развернутые модели взимается плата. Когда вы закончите делать онлайн прогнозы, вы можете отменить развертывание своей модели, чтобы избежать дополнительных затрат на развертывание. Узнать больше.
Модели должны периодически проходить переобучение, чтобы они могли продолжать служить
предсказания. Для прогнозов без важности признаков модель должна быть
переподготовка каждые два года.Для прогнозов с важностью признаков модель
необходимо проходить переподготовку каждые полгода.
Для прогнозов без важности признаков модель должна быть
переподготовка каждые два года.Для прогнозов с важностью признаков модель
необходимо проходить переподготовку каждые полгода.
Получение онлайн-прогноза
Консоль
Как правило, онлайн-прогнозы используются для получения прогнозов из бизнес-приложения. Однако вы можете использовать таблицы AutoML в Облачная консоль для тестирования вашего формата данных или вашей модели с определенным набор ввода.
Посетите страницу таблиц AutoML в Google Cloud Console.
Перейти на страницу таблиц AutoML
Выберите Модели и выберите модель, которую хотите использовать.
Выберите вкладку Test & Use и нажмите Онлайн-прогноз .
Если ваша модель еще не развернута, разверните ее сейчас, щелкнув Развернуть модель .
Ваша модель должна быть развернута, чтобы использовать онлайн-прогнозы. Развертывание вашей модели несет расходы. Для получения дополнительной информации см. страницу с ценами.
Введите введенные значения в соответствующие текстовые поля.
Кроме того, вы можете выбрать JSON Code View , чтобы указать свой ввод. значения в формате JSON.
Если вы хотите увидеть, как каждая функция повлияла на прогноз, выберите Создание важности функции .
Google Cloud Console усекает локальный значения важности функции для удобочитаемости. Если вам нужно точное значение, используйте Cloud AutoML API, чтобы сделать запрос прогноза.
Сведения о важности функций см. Важность местных особенностей.
Нажмите Predict , чтобы получить свой прогноз.
Для получения информации об интерпретации результатов вашего прогноза см. Интерпретация результатов вашего прогноза. Для получения информации о важности локальных объектов см. см. Важность локальных объектов.
(необязательно) Если вы не планируете запрашивать больше онлайн-прогнозов, вы можно отменить развертывание вашей модели, чтобы избежать расходов на развертывание, нажав Отменить развертывание модели .

завиток
Вы запрашиваете прогноз для набора значений по
создание вашего объекта JSON с вашими значениями функций, а затем использование model.predict метод для получения прогноза.
Значения должны содержать именно те столбцы, которые вы включили в обучение, и они
должны быть в том же порядке, как показано на вкладке Оценить , щелкнув
по ссылке включенных столбцов.
Если вы хотите изменить порядок значений, вы можете дополнительно включить набор столбцов идентификаторы спецификаций в порядке значений.Вы можете получить идентификаторы спецификаций столбцов из объект модели; они находятся в TablesModelMetadata.inputFeatureColumnSpecs поле.
Тип данных каждого значения (признака) в объекте Row зависит от Тип данных AutoML Tables для функции. Список принимаемых данных типы по типу данных AutoML Tables, см. раздел Формат объекта Row.
Если вы еще не развернули свою модель, разверните ее сейчас. Узнать больше.
Запрос прогноза.
Прежде чем использовать какие-либо данные запроса, сделать следующие замены:
- конечная точка :
автом.googleapis.comдля глобального местоположения иeu-automl.googleapis.comдля региона ЕС. - идентификатор проекта : идентификатор вашего проекта Google Cloud.
- адрес : адрес ресурса:
us-central1для всего мира илиeuдля Европейского союза. - идентификатор модели : идентификатор модели. Например,
TBL543. - valueN : значения для каждого столбца в правильном порядке.
HTTP-метод и URL-адрес:
POST https:// конечная точка /v1beta1/projects/ идентификатор проекта /locations/ местоположение /models/ идентификатор модели :прогноз
Тело запроса JSON:
{ "полезная нагрузка": { "ряд": { "значения": [ значение1 , значение2 ,. ..
]
}
}
}
Чтобы отправить запрос, выберите один из следующих вариантов:
завиток
Сохраните тело запроса в файле с именем
request.json, и выполните следующую команду:curl -X POST \
-H "Авторизация: носитель" $(gcloud auth application-default print-access-token) \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https:// конечная точка /v1beta1/projects/ идентификатор проекта /locations/ местоположение /models/ идентификатор модели :predict"PowerShell
Сохраните тело запроса в файле с именем
request., и выполните следующую команду: json $cred = gcloud auth application-default print-access-token
Чтобы включить результаты важности локальных объектов, включите
$headers = @{ "Authorization" = "Bearer $cred" }Invoke-WebRequest `
- Method POST `
- Headers $headers `
- ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https:// конечная точка /v1beta1/projects/ идентификатор проекта /locations/ местоположение /models/ идентификатор модели : предсказать" | Select-Object-Expand Contentпараметр feature_importance.Для получения дополнительной информации о местной функции важности, см. Важность локальных объектов.- конечная точка :
Просмотрите свои результаты.
Для модели классификации вы должны увидеть вывод, аналогичный следующему пример. Обратите внимание, что возвращаются два результата, каждый с доверительной оценкой (
баллов). Оценка достоверности находится в диапазоне от 0 до 1 и показывает, насколько вероятно модель считает, что это правильное значение прогноза. Чтобы получить больше информации о том, как использовать доверительную оценку, см. Интерпретация результатов вашего прогноза.{ "полезная нагрузка": [ { "столы": { "счет": 0,11210235, "значение": "1" } }, { "столы": { "счет": 0,8878976, "значение": "2" } } ] }Для модели регрессии результаты включают значение прогноза и интервал предсказания. Интервал прогнозирования обеспечивает диапазон, который включает истинное значение в 95% случаев (на основе данных, которые модель обучила на).
Обратите внимание, что прогнозируемое значение может быть не в центре интервала (оно
может даже выйти за пределы интервала), потому что интервал прогнозирования
центрируется вокруг медианы, тогда как прогнозируемое значение является ожидаемым значением
(или среднее).{ "полезная нагрузка": [ { "столы": { "значение": 207.18209838867188, "интервал предсказания": { "старт": 29.712770462036133, "конец": 937.42041015625 } } } ] }Для получения информации о результатах важности локальных объектов, см. Важность локальных объектов.
(необязательно) Если вы закончили запрашивать онлайн-прогнозы, вы можете отменить развертывание модели, чтобы избежать расходов на развертывание. Узнать больше.
 ..
]
}
}
}
..
]
}
}
}
 json
json  Важность локальных объектов.
Важность локальных объектов. Обратите внимание, что прогнозируемое значение может быть не в центре интервала (оно
может даже выйти за пределы интервала), потому что интервал прогнозирования
центрируется вокруг медианы, тогда как прогнозируемое значение является ожидаемым значением
(или среднее).
Обратите внимание, что прогнозируемое значение может быть не в центре интервала (оно
может даже выйти за пределы интервала), потому что интервал прогнозирования
центрируется вокруг медианы, тогда как прогнозируемое значение является ожидаемым значением
(или среднее).Ява
Если ваши ресурсы расположены в регионе ЕС, вы должны явно указать конечную точку. Узнать больше.
Узнать больше.
Node.js
Если ваши ресурсы расположены в регионе ЕС, вы должны явно указать конечную точку. Узнать больше.
Питон
Клиентская библиотека для таблиц AutoML включает дополнительные методы Python, которые упрощают использование
API таблиц AutoML.Эти методы обращаются к наборам данных и моделям по имени, а не по идентификатору. Твой
имена наборов данных и моделей должны быть уникальными. Для получения дополнительной информации см. Справка клиента.
Справка клиента.
Если ваши ресурсы расположены в регионе ЕС, вы должны явно указать конечную точку. Узнать больше.
Что дальше
Понимание гипотез и прогнозов — академические навыки
Гипотезы и прогнозы — это разные компоненты научного метода.Научный метод — это систематический процесс, который помогает свести к минимуму предвзятость в исследованиях и начинается с разработки хороших исследовательских вопросов.
Исследовательские вопросы
Вопросы описательного исследования основаны на наблюдениях, сделанных в ходе предыдущего исследования или мимоходом. Этот тип исследовательского вопроса часто дает количественную оценку этих наблюдений. Например, во время наблюдения за птицами вы заметили, что определенный вид воробьев построил все свои гнезда из одного и того же материала: травы. Описательный вопрос исследования будет звучать так: «В среднем, сколько травы используется для строительства воробьиных гнезд?»
Описательный вопрос исследования будет звучать так: «В среднем, сколько травы используется для строительства воробьиных гнезд?»
Описательные исследовательские вопросы ведут к причинно-следственным вопросам.Этот тип исследовательского вопроса направлен на то, чтобы понять, почему мы наблюдаем определенные тенденции или закономерности. Если мы вернемся к нашему наблюдению о воробьиных гнездах, каузальным вопросом будет: «Почему воробьиные гнезда сделаны из травы, а не из веток?»
Гипотеза
Проще говоря, гипотеза – это ответ на причинно-следственный вопрос. Гипотеза должна основываться на сильном обосновании, которое обычно подтверждается предварительными исследованиями. Из вопроса о воробьиных гнездах вы можете предположить: «Воробьи используют траву в своих гнездах, а не ветки, потому что травы являются более распространенным материалом в их среде обитания.Эта гипотеза изобилия может быть подтверждена вашими предварительными знаниями о наличии строительных материалов для гнезд (т. е. травы больше, чем веток).
Предсказание
С другой стороны, предсказание – это результат, который вы бы наблюдали, если бы ваша гипотеза была верна. Прогнозы часто записываются в форме утверждений «если и, то», например, «если моя гипотеза верна, и я должен был провести этот тест, то это то, что я буду наблюдать». Следуя нашему примеру с воробьем, вы можете предположить, что «если воробьи используют траву, потому что она более многочисленна, и я сравниваю области, где веток больше, чем доступной травы, то в этих областях гнезда должны быть сделаны из веток.Более точный прогноз может изменить формулировку, чтобы не повторять гипотезу дословно: «Если воробьи выбирают материалы для гнезд в зависимости от их изобилия, то, когда веточек будет больше, воробьи будут использовать те, что находятся в их гнездах».
Как видите, термины гипотеза и предсказание различны и различны, хотя иногда они неправильно используются как синонимы.
Пример
Давайте посмотрим на другой пример:
Причинный вопрос: почему спаржевых жуков меньше, когда спаржу выращивают рядом с бархатцами?
Гипотеза: Бархатцы отпугивают спаржевых жуков.
Предсказание: Если бархатцы отпугивают спаржевых жуков, и мы выращиваем спаржу рядом с бархатцами, то мы должны обнаружить меньше спаржевых жуков, когда растения спаржи засажены бархатцами.
Последнее замечание
Приятно, когда результаты вашего исследования или эксперимента подтверждают вашу гипотезу. Однако это может быть не менее увлекательно, если этого не произойдет. Есть много причин, по которым вы можете получить неожиданный результат, и вам нужно подумать, почему это произошло. Возможно, у вас были потенциальные проблемы с вашими методами, но, с другой стороны, возможно, вы только что обнаружили новую линию доказательств, которые можно использовать для разработки другого эксперимента или исследования.
Точность, справедливость и пределы прогнозирования рецидивизма
Мы сравниваем общую точность и погрешность оценки человека с алгоритмической оценкой COMPAS. Повсюду положительный прогноз — это тот, в котором обвиняемому предсказывается рецидив, тогда как отрицательный прогноз — это тот, в котором он не предсказывает рецидива. Мы измеряем общую точность как уровень, при котором ответчик правильно предсказывает рецидив или нет (то есть объединенные показатели истинно-положительных и истинно-отрицательных результатов).Мы также сообщаем о ложноположительных результатах (прогнозируется, что обвиняемый будет рецидивировать, но он этого не делает) и ложноотрицательных (прогнозируется, что ответчик не будет рецидивировать, но он это делает).
Мы измеряем общую точность как уровень, при котором ответчик правильно предсказывает рецидив или нет (то есть объединенные показатели истинно-положительных и истинно-отрицательных результатов).Мы также сообщаем о ложноположительных результатах (прогнозируется, что обвиняемый будет рецидивировать, но он этого не делает) и ложноотрицательных (прогнозируется, что ответчик не будет рецидивировать, но он это делает).
Человеческая оценка
Участники видели краткое описание подсудимого, которое включало пол, возраст и предыдущую криминальную историю подсудимого, но не его расу (см. Материалы и методы). Участники предсказали, совершит ли этот человек рецидив в течение 2 лет после совершения последнего преступления. Мы использовали в общей сложности 1000 описаний подсудимых, которые были случайным образом разделены на 20 подмножеств по 50 в каждом.Чтобы сделать задачу выполнимой, каждому участнику случайным образом поручили увидеть одно из этих 20 подмножеств. Средняя и медианная точность этих прогнозов составляет 62,1 и 64,0%.
Мы сравниваем эти результаты с работой COMPAS на этой подгруппе из 1000 ответчиков. Поскольку группы из 20 участников судили одну и ту же подгруппу из 50 подсудимых, индивидуальные решения не являются независимыми. Однако, поскольку каждый участник оценивал только одну подгруппу ответчиков, медианные значения точности каждой подгруппы можно разумно считать независимыми.Таким образом, производительность участников на 20 подмножествах можно напрямую сравнить с производительностью COMPAS на тех же 20 подмножествах. Односторонний тест t показывает, что среднее значение точности 20 участников, равное 62,8 % [и стандартное отклонение (SD) 4,8 %], едва ли ниже, чем точность COMPAS, составляющая 65,2 % ( P = 0,045).
Чтобы определить, есть ли «мудрость в толпе» ( 7 ) (в нашем случае небольшая группа из 20 человек на подмножество), ответы участников были объединены в каждом подмножестве с использованием критерия правил большинства.Этот подход на основе толпы дает точность предсказания 67,0%. Односторонний тест t показывает, что COMPAS незначительно лучше толпы ( P = 0,85).
Односторонний тест t показывает, что COMPAS незначительно лучше толпы ( P = 0,85).Точность прогноза также можно оценить с помощью AUC-ROC. AUC-ROC для наших участников составляет 0,71 ± 0,03, что почти идентично 0,70 ± 0,04 COMPAS.
Точность прогноза также можно оценить с помощью инструментов теории обнаружения сигналов, в которых точность выражается через чувствительность ( d ′) и погрешность (β).Более высокие значения d ′ соответствуют большей чувствительности участников. Значение d ′ = 0 означает, что участник не имеет информации для надежной идентификации, независимо от того, какое у него может быть предубеждение. Значение β = 1,0 указывает на отсутствие предвзятости, значение β > 1 указывает на то, что участники склонны классифицировать ответчика как не подверженного риску рецидива, а β < 1 указывает на то, что участники предвзято классифицируют ответчика как подверженного риску рецидива.С d ′ 0,86 и β 1,02 наши участники немного более чувствительны и немного менее предвзяты, чем COMPAS с d ′ 0,77 и β 1,08.
Имея значительно меньше информации, чем COMPAS (всего 7 функций по сравнению со 137 функциями COMPAS), небольшая группа неспециалистов так же точно, как COMPAS, предсказывает рецидивы. Кроме того, прогнозы наших участников и COMPAS совпали для 692 из 1000 ответчиков.
Справедливость
Мы измеряем честность наших участников в отношении гонки ответчика на основе прогнозов толпы.Точность наших участников в отношении чернокожих ответчиков составляет 68,2% по сравнению с 67,6% для белых ответчиков. Непарный тест t не выявил существенных различий между расами ( P = 0,87). Это аналогично COMPAS, который имеет точность 64,9% для чернокожих респондентов и 65,7% для белых респондентов, что также существенно не отличается ( P = 0,80, непарный тест t ). По этой мере справедливости наши участники и COMPAS справедливы по отношению к черным и белым ответчикам.
Уровень ложноположительных результатов у наших участников для чернокожих ответчиков составляет 37,1% по сравнению с 27,2% для белых ответчиков. Непарный тест t показывает значительную разницу между расами ( P = 0,027). Уровень ложноотрицательных результатов наших участников для чернокожих ответчиков составляет 29,2% по сравнению с 40,3% для белых ответчиков. Непарный тест t показывает значительную разницу между расами ( P = 0,034). Эти расхождения аналогичны расхождениям COMPAS, у которых частота ложноположительных результатов составляет 40.4% для темнокожих респондентов и 25,4% для белых респондентов, которые существенно различаются ( P = 0,002, непарный тест t ). Частота ложноотрицательных результатов COMPAS для темнокожих респондентов составляет 30,9% по сравнению с 47,9% для белых респондентов, которые значительно различаются ( P = 0,003, непарный тест t ). По этой мере справедливости наши участники и COMPAS одинаково несправедливы по отношению к чернокожим ответчикам, несмотря на то, что раса явно не указана. См. таблицу 1 [столбцы (A) и (C)] и рис.1 для краткого изложения этих результатов.
Непарный тест t показывает значительную разницу между расами ( P = 0,027). Уровень ложноотрицательных результатов наших участников для чернокожих ответчиков составляет 29,2% по сравнению с 40,3% для белых ответчиков. Непарный тест t показывает значительную разницу между расами ( P = 0,034). Эти расхождения аналогичны расхождениям COMPAS, у которых частота ложноположительных результатов составляет 40.4% для темнокожих респондентов и 25,4% для белых респондентов, которые существенно различаются ( P = 0,002, непарный тест t ). Частота ложноотрицательных результатов COMPAS для темнокожих респондентов составляет 30,9% по сравнению с 47,9% для белых респондентов, которые значительно различаются ( P = 0,003, непарный тест t ). По этой мере справедливости наши участники и COMPAS одинаково несправедливы по отношению к чернокожим ответчикам, несмотря на то, что раса явно не указана. См. таблицу 1 [столбцы (A) и (C)] и рис.1 для краткого изложения этих результатов.
| 1 (а) Человека (без расы) | (б) человек | 1 (гонка) | (c) COPAS | |||
|---|---|---|---|---|---|---|
| Точность (в целом ) | 67,0% | 66,5% | 66,5% | 65,2% | ||
| AUC-ROC (в целом) | 0.71 | 0.71 | 0.70 | |||
| D ‘/ β (в целом) | 0.86 / 1.02 | 0.02 / 1.03 | 0.83 / 1.03 | 0,77 / 1.08 | 0.77 / 1.08 | |
| Точность (черный) | 68,2% | 66,2% | 64,9% | |||
| Точность (белый) | 67,6% | 67,6% | 65,7% | |||
| ложный положительный (черный) | 37. 1% 1% | 37,1% | 40,0% | 40.4% | ||
| Ложный положительный (белый) | 27,2% | 26,2% | 25,4% | |||
| False негатив (черный) | 29.2% | 30,1% | 30,4% | 30,9% | 30,9% | |
| ЛОЖНЫЙ ОТЛИЧНЫЙ (белый) | 40,3% | 42,1% | 42,4% |
Таблица 1 человека против компазов Алгоритмические прогнозы от 1000 подсудимых.
Общая точность определяется как процент правильности, AUC-ROC, чувствительность критерия ( d ′) и погрешность (β). См. также рис. 1. Рис. 1 Человек (состояние отсутствия гонки) по сравнению с алгоритмическими прогнозами COMPAS (см. также Таблицу 1).
Предсказание с учетом расы
В этом втором условии вновь набранная группа из 400 участников повторила то же исследование, но с включением расы респондента.Мы задались вопросом, уменьшит ли включение расы обвиняемого или преувеличит влияние любого скрытого, явного или институционального расового предубеждения. В этом состоянии средняя и медианная точность предсказания рецидива ответчика составляет 62,3 и 64,0%, что почти идентично состоянию, когда раса не указана.
Точность на основе толпы составляет 66,5%, что немного ниже, чем при условии, что раса не указана, но существенно не отличается ( P = 0,66, парный тест t ).AUC-ROC на основе толпы составляет 0,71 ± 0,03, а d ′ / β составляет 0,83 / 1,03, что аналогично предыдущему условию отсутствия гонки [Таблица 1, столбцы (A) и (B)]. Что касается справедливости. , точность участников существенно не отличается для чернокожих респондентов (66,2%) по сравнению с белыми респондентами (67,6%; P = 0,65, непарный тест t ). Уровень ложноположительных результатов для чернокожих ответчиков составляет 40,0% по сравнению с 26,2% для белых ответчиков. Непарный тест t показывает значительную разницу между расами ( P = 0.001). Частота ложноотрицательных результатов для чернокожих ответчиков составляет 30,1% по сравнению с 42,1% для белых ответчиков, что, опять же, значительно отличается ( P = 0,030, непарный тест t ). См. Таблицу 1 [столбец (B)] для сводки этих результатов.
Уровень ложноположительных результатов для чернокожих ответчиков составляет 40,0% по сравнению с 26,2% для белых ответчиков. Непарный тест t показывает значительную разницу между расами ( P = 0.001). Частота ложноотрицательных результатов для чернокожих ответчиков составляет 30,1% по сравнению с 42,1% для белых ответчиков, что, опять же, значительно отличается ( P = 0,030, непарный тест t ). См. Таблицу 1 [столбец (B)] для сводки этих результатов.В заключение, нет достаточных доказательств того, что включение расы оказывает значительное влияние на общую точность или справедливость. Исключение расы не обязательно ведет к устранению расовых различий в предсказании рецидивизма среди людей.
Демографические данные участников
Наши участники были в возрасте от 18 до 74 лет (один участник старше 75 лет) и с уровнем образования от «ниже среднего» до «профессиональная степень». Ни возраст, ни пол, ни уровень образования не оказали существенного влияния на точность участников. Было недостаточно небелых участников, чтобы надежно измерить какие-либо различия между расами участников.
Было недостаточно небелых участников, чтобы надежно измерить какие-либо различия между расами участников.
Алгоритмическая оценка
Поскольку неспециалисты так же точны, как и программное обеспечение COMPAS, мы задались вопросом о сложности алгоритма прогнозирования COMPAS.Программное обеспечение COMPAS от Northpointe включает 137 различных функций для прогнозирования рецидивизма. С общей точностью около 65% эти прогнозы не так точны, как хотелось бы, особенно с точки зрения ответчика, чье будущее находится на волоске.
Northpointe не раскрывает подробности внутренней работы COMPAS — это понятно, учитывая их коммерческие интересы. Однако мы обнаружили, что простой линейный предиктор — логистическая регрессия (LR) (см. «Материалы и методы») — с теми же семью характеристиками, что и у наших участников (в условиях отсутствия гонки), дает такую же точность предсказания, как COMPAS.По сравнению с общей точностью КОМПАСа 65,4%, классификатор LR дает общую точность тестирования 66,6%. Этот предиктор дает аналогичные COMPAS результаты с точки зрения прогностической справедливости [таблица 2, столбцы (A) и (D)].
Этот предиктор дает аналогичные COMPAS результаты с точки зрения прогностической справедливости [таблица 2, столбцы (A) и (D)].| (а) LR 7 | (б) LR 2 | (C) NL-SVM | 1 (D) Compas | ||
|---|---|---|---|---|---|
| Точность (общая) | 66.6% [64.4, 68,9] | 66,8% [64.3, 69.2] | 65,2% [63,0, 67.2] | 65,4% [64.3, 66,5] | |
| Точность (черный) | 66,7% [63,6, 69,6 ] | 66,7% [63.5, 69.2] | 64,3% [61.1, 67.7] | 63,8% [62.2, 65,4] | |
| Точность (белый) | 66,0% [62,6, 69,6] | 66,4% [ 62,6, 70,1] | 65,3% [61,4, 69,0] | 67,0% [65,1, 68,9] | |
| Ложноположительный (черный) | 42. 9% [37.7, 48,0] 9% [37.7, 48,0] | , 45,6% [39,9, 51.1] | , 51,1] | 31,6% [26.4, 36,7] | 44,8% [42,7, 46,98] |
| Ложное положительное (белое) | 25,3% [20.1, 30.2] | 25,3% [20.6, 30.5] | 20,5% [16.1, 25,0] | 23,5% [20.7, 26,5] | |
| Ложно отрицательный (черный) | 24,2% [20.1, 28.2] | 21.6 % [17,5, 25,9] | 39,6% [34,2, 45,0] | 28,0% [25,7, 30,3] | |
| Ложноотрицательный (белый) | 47.3% [40.8, 54,0] | 46,1% [40,0, 52,7] | 56,6% [50.3, 63,5] | 47,7% [45.2, 50.2] |
Таблица 2 Алгоритмические прогнозы от 7214 подсудимых.
Логистическая регрессия с 7 признаками (A) (LR 7 ), логистическая регрессия с 2 признаками (B) (LR 2 ), нелинейная SVM с 7 признаками (C) (NL-SVM) и коммерческая Программное обеспечение COMPAS со 137 функциями (D) (COMPAS). Результаты в столбцах (A), (B) и (C) соответствуют средней точности тестирования по 1000 случайным разделениям обучения/тестирования 80%/20%.Значения в квадратных скобках соответствуют 95%-му доверительному интервалу [столбцы (A), (B) и (C)] и биномиальному [столбец (D)].
Результаты в столбцах (A), (B) и (C) соответствуют средней точности тестирования по 1000 случайным разделениям обучения/тестирования 80%/20%.Значения в квадратных скобках соответствуют 95%-му доверительному интервалу [столбцы (A), (B) и (C)] и биномиальному [столбец (D)].
Несмотря на то, что в качестве входных данных используются только 7 признаков, стандартный линейный предиктор дает результаты, аналогичные предсказателю COMPAS со 137 признаками. Мы можем обоснованно заключить, что COMPAS не использует ничего более сложного, чем линейный предиктор или его аналог.
Чтобы проверить, ограничена ли производительность классификатором или характером данных, мы обучили более мощную нелинейную машину опорных векторов (NL-SVM) на тех же данных.Несколько удивительно, что NL-SVM дает почти идентичные результаты с линейным классификатором [таблица 2, столбец (C)]. Если бы относительно низкая точность линейного классификатора была связана с тем, что данные не являются линейно разделимыми, то можно было бы ожидать, что NL-SVM будет работать лучше. Неспособность сделать это предполагает, что данные просто неразделимы линейно или иначе. Наконец, мы задались вопросом, будет ли использование еще меньшего подмножества из 7 признаков таким же точным, как использование 137 признаков COMPAS. Мы обучили и протестировали LR-классификатор на всех возможных подмножествах семи признаков.Классификатор, основанный только на двух признаках — возрасте и общем количестве судимостей — работает так же, как КОМПАС; см. Таблицу 2 [столбец (B)]. Важность этих двух критериев согласуется с выводами двух метаанализов, целью которых было, в частности, определить, какие критерии наиболее предсказуемы в отношении рецидивизма ( 8 , 9 ).
Неспособность сделать это предполагает, что данные просто неразделимы линейно или иначе. Наконец, мы задались вопросом, будет ли использование еще меньшего подмножества из 7 признаков таким же точным, как использование 137 признаков COMPAS. Мы обучили и протестировали LR-классификатор на всех возможных подмножествах семи признаков.Классификатор, основанный только на двух признаках — возрасте и общем количестве судимостей — работает так же, как КОМПАС; см. Таблицу 2 [столбец (B)]. Важность этих двух критериев согласуется с выводами двух метаанализов, целью которых было, в частности, определить, какие критерии наиболее предсказуемы в отношении рецидивизма ( 8 , 9 ).Использование моделей для прогнозирования
1. Активизировать предварительные знания учащихся о парниковых газах и глобальном потеплении.
Скажите учащимся, что они будут выяснять, насколько необходимо снизить концентрацию парниковых газов, чтобы предотвратить сильное потепление атмосферы Земли. Рассмотрите вместе с учащимися взаимодействие парниковых газов с радиацией и температурой, а также с поверхностью и температурой Земли. Спросите:
Рассмотрите вместе с учащимися взаимодействие парниковых газов с радиацией и температурой, а также с поверхностью и температурой Земли. Спросите:
- Как парниковые газы вызывают потепление атмосферы? (Парниковые газы поглощают уходящее инфракрасное излучение и переизлучают его, удерживая тепловую энергию в атмосфере.)
- Как уровень углекислого газа в атмосфере влияет на уровень водяного пара в атмосфере? (Чем больше в атмосфере углекислого газа, тем больше в атмосфере будет водяного пара.Углекислый газ повышает температуру, что приводит к повышенному испарению воды. Это приводит к большему потеплению и большему количеству углекислого газа в атмосфере, поскольку он высвобождается из океанов, и большему количеству водяного пара, поскольку больше воды испаряется. Это положительная обратная связь.)
- Как цвет поверхности Земли влияет на температуру? (Когда поверхность светлая, солнечное излучение отражается, что приводит к меньшему нагреву. Когда поверхность темного цвета, солнечное излучение поглощается, что приводит к большему нагреву.)
 Когда поверхность темного цвета, солнечное излучение поглощается, что приводит к большему нагреву.)
Когда поверхность темного цвета, солнечное излучение поглощается, что приводит к большему нагреву.)- Какая связь между водяным паром и облаками? (Чем больше водяного пара, тем больше облаков. Облака могут отражать солнечное излучение, что приводит к охлаждению, что может уменьшить количество водяного пара в воздухе. Это отрицательная обратная связь.)
2. Обсудите роль неопределенности в научном процессе.
Наука — это процесс изучения того, как устроен мир, и что ученые не знают «правильных» ответов, когда начинают исследовать вопрос.Скажите учащимся, что они могут видеть примеры неуверенности ученых в прогнозировании климата.
Покажите График изменения глобальной температуры из отчета МГЭИК (Межправительственной группы экспертов по изменению климата) 1995 года. Скажите учащимся, что на этом графике показано несколько различных моделей прогнозируемых изменений температуры. Спросите: Почему в более поздние периоды между моделями больше различий (более широкий разброс), чем в более близкие даты? (Между моделями более поздних дат больше различий, чем более близких, потому что существует большая вариативность в предсказании далекого будущего, чем в предсказании ближайшего будущего.)
Спросите: Почему в более поздние периоды между моделями больше различий (более широкий разброс), чем в более близкие даты? (Между моделями более поздних дат больше различий, чем более близких, потому что существует большая вариативность в предсказании далекого будущего, чем в предсказании ближайшего будущего.)
Сообщите учащимся, что способность лучше предсказывать краткосрочные события возникает также при прогнозировании ураганов и тропических штормов. Проект Определение конуса прогноза траектории Национального центра ураганов и покажите учащимся «конус неопределенности» вокруг траектории урагана. Скажите учащимся, что конус показывает неуверенность ученых в траектории шторма, точно так же, как климатические модели показывают неуверенность ученых в том, насколько изменится температура Земли в будущем.
Спросите: Когда ученые наиболее уверены в своих предсказаниях? (Ученые наиболее уверены в своих предсказаниях, когда у них много данных. Вот почему прогнозы краткосрочных событий лучше, чем прогнозы долгосрочных, как при прогнозировании штормов, так и при прогнозировании климата.)
Вот почему прогнозы краткосрочных событий лучше, чем прогнозы долгосрочных, как при прогнозировании штормов, так и при прогнозировании климата.)
Сообщите учащимся, что им будут заданы вопросы о достоверности их предсказаний, и что им нужно будет подумать о том, какие научные данные доступны, когда они будут оценивать свою достоверность в своих ответах.Предложите учащимся обсудить научные данные друг с другом, чтобы лучше оценить свой уровень уверенности в своих прогнозах.
3. Обсудите роль систем в науке о климате.
Скажите учащимся, что прогнозирование того, что произойдет в климатической системе Земли, является сложным процессом, поскольку существует множество различных взаимодействующих частей. Ученые думают о том, как одна часть системы может влиять на другие части системы. Дайте учащимся простой пример системы, как описано в приведенном ниже сценарии.
На острове есть популяция лис и популяция кроликов. Лисы охотятся на кроликов. Спросите:
Лисы охотятся на кроликов. Спросите:
- Когда будет много кроликов, что произойдет с популяцией лис? (Он увеличится, потому что еды достаточно.)
- Что происходит с популяцией лис, когда они съедают большую часть кроликов? (Лисы умрут от голода, так как их запасы пищи уменьшатся.)
- Что происходит с количеством травы, когда популяция лис высока? (Количество травы увеличится, потому что меньше кроликов едят траву.)
- Если будет засуха и трава будет плохо расти, что будет с популяциями лис и кроликов? (Популяция кроликов уменьшится, потому что у них будет меньше пищи. Популяция лис также должна уменьшиться по мере уменьшения их еды.)
Люди завезли на остров собак. Собаки соревнуются с лисами за корм для кроликов. Спросите: Что произойдет с популяциями лисиц, кроликов и травы после появления собак? (Количество лисиц уменьшится, потому что они делят свои запасы пищи, количество кроликов уменьшится, потому что у них больше хищников, а трава станет лучше из-за меньшего воздействия меньшей популяции кроликов. )
)
Скажите учащимся, что эти простые причинно-следственные связи могут трансформироваться в более сложные системные отношения. Сообщите учащимся, что в этом упражнении они будут изучать причинно-следственные связи и системную обратную связь между углекислым газом и водяным паром. Попросите учащихся подумать о том, как каждая часть системы влияет на другие части системы.
4. Представьте и обсудите использование вычислительных моделей.
Познакомьте с концепцией вычислительных моделей и дайте учащимся пример вычислительной модели, которую они могли видеть, например прогноз погоды. Спроектируйте модель прогноза погоды NOAA , которая представляет собой хороший пример вычислительной модели. Скажите ученикам, что:
- Ученые используют информацию о прошлом для построения своих климатических моделей.
- ученых проверяют свои климатические модели, используя их для прогнозирования климата в прошлом.
- , когда ученые могут точно прогнозировать климат в прошлом, они могут быть более уверенными в использовании своих моделей для прогнозирования климата в будущем.

5. Предложите учащимся запустить интерактивный раздел Использование моделей для составления прогнозов.
Предоставьте учащимся ссылку на интерактивное использование моделей для прогнозирования. Разделите учащихся на группы по два или три человека, причем двое — это идеальная группа, позволяющая учащимся совместно использовать компьютерное рабочее место.Скажите учащимся, что они будут работать с серией страниц моделей с вопросами, связанными с моделями. Попросите учащихся выполнить упражнение в своих группах, обсуждая и отвечая на вопросы по ходу дела.
ПРИМЕЧАНИЕ: Вы можете получить доступ к ключу ответов на вопросы учащихся и сохранить данные учащихся для онлайн-оценки, пройдя бесплатную регистрацию на странице портала High-Adventure Science.
Скажите учащимся, что это задание 6 урока Каково будущее климата Земли?
6.Предложите учащимся обсудить то, что они узнали в этом упражнении.
После того, как учащиеся выполнили задание, снова соберите группы и проведите обсуждение, сосредоточив внимание на следующих вопросах:
- Нужны ли модели для понимания изменения климата? (Нет. Основная причина потепления Земли понятна без моделей, но взаимодействия достаточно сложны, чтобы модели помогли полностью понять все взаимосвязи между компонентами климатической системы Земли.)
- Как определить, что результаты климатической модели достоверны? (Когда климатическая модель может точно предсказывать климат в прошлом, вы можете быть более уверены в ее способности предсказывать климат в будущем. Если входные данные для модели достаточно хороши для предсказания прошлого, их должно быть достаточно, чтобы дать хорошее представление о будущее. )
 )
) - В модели системы Земли с ползунком выбросов человека (модель 8) , насколько необходимо было уменьшить выбросы парниковых газов, чтобы предотвратить слишком сильное повышение температуры? (Модель показывает, что необходимо снижение на 50-75%.Однако в этой модели отсутствуют многие факторы. Он не показывает нагревающий эффект облаков или океанских течений, которые могут влиять на глобальные температуры.)
Инструмент для оценки риска рака молочной железы
Инструмент оценки риска рака молочной железы позволяет медицинским работникам оценить риск развития инвазивного рака молочной железы у женщины в течение следующих 5 лет и до 90 лет (пожизненный риск).
Инструмент использует личную медицинскую и репродуктивную историю женщины и историю рака молочной железы среди ее родственников первой степени (матери, сестер, дочерей).
оценить абсолютный риск рака молочной железы — ее шанс или вероятность развития инвазивного рака молочной железы в определенном возрастном интервале.
Инструмент был одобрен для белых женщин, чернокожих/афроамериканок, латиноамериканок и женщин азиатских и тихоокеанских островов в Соединенных Штатах. Инструмент может недооценивать риск у чернокожих женщин с предыдущими биопсиями и латиноамериканских женщин, родившихся за пределами Соединенных Штатов. Поскольку данные о женщинах из числа американских индейцев/коренных жителей Аляски ограничены, их оценки риска частично основаны на данных для белых женщин и могут быть неточными.Необходимы дальнейшие исследования для уточнения и проверки этих моделей.
Этот инструмент не может точно оценить риск рака молочной железы для:
- Женщины с мутацией гена BRCA1 или BRCA2, вызывающей рак молочной железы
- Женщины с инвазивным или инвазивным раком молочной железы в анамнезе (дольковая карцинома in situ или протоковая карцинома in situ)
- Женщины в некоторых других подгруппах (см. раздел «Другие инструменты оценки риска»)
 раздел «Другие инструменты оценки риска»)
раздел «Другие инструменты оценки риска»)Хотя риск для женщины можно точно оценить, эти прогнозы не позволяют точно сказать, у какой женщины разовьется рак молочной железы.Фактически, у некоторых женщин, у которых не развивается рак молочной железы, оценки риска выше, чем у некоторых женщин, у которых рак молочной железы развивается.
Как делать прогнозы для прогнозирования временных рядов с помощью Python
Последнее обновление: 24 апреля 2020 г.
Выбор модели прогнозирования временных рядов — это только начало.
При использовании выбранной модели на практике могут возникнуть проблемы, включая преобразование данных и сохранение параметров модели на диске.
В этом руководстве вы узнаете, как завершить модель прогнозирования временных рядов и использовать ее для прогнозирования в Python.
После прохождения этого урока вы будете знать:
- Как доработать модель и сохранить ее и необходимые данные в файл.
- Как загрузить готовую модель из файла и использовать ее для прогнозирования.
- Как обновить данные, связанные с окончательной моделью, чтобы сделать последующие прогнозы.

Начните свой проект с моей новой книги «Прогнозирование временных рядов с помощью Python», включающей пошаговых руководств и файлы с исходным кодом Python для всех примеров.
Начнем.
- Обновлено за февраль 2017 г. : обновлен макет и имена файлов, чтобы отделить дело AR от дела вручную.
- Обновлено, апрель 2019 г. : обновлена ссылка на набор данных.
- Обновлено, август 2019 г. : обновлена загрузка CSV-файла.
- Обновлено за апрель 2020 г. : AR изменен на AutoReg из-за изменения API.
Как делать прогнозы для прогнозирования временных рядов с помощью Python
Фото Джо Кристиансена, некоторые права защищены.
Процесс создания прогноза
Много написано о том, как настроить конкретные модели прогнозирования временных рядов, но мало помощи дается о том, как использовать модель для прогнозирования.
После того, как вы сможете создавать и настраивать модели прогнозов для своих данных, процесс прогнозирования включает следующие этапы:
- Выбор модели . Здесь вы выбираете модель и собираете доказательства и поддержку для защиты решения.
- Доработка модели .Выбранная модель обучается на всех доступных данных и сохраняется в файл для последующего использования.
- Прогнозирование . Сохраненная модель загружается и используется для составления прогноза.
- Обновление модели . Элементы модели обновляются при наличии новых наблюдений.
В этом руководстве мы рассмотрим каждый из этих элементов, уделив особое внимание сохранению и загрузке модели в файл и из файла, а также использованию загруженной модели для прогнозирования.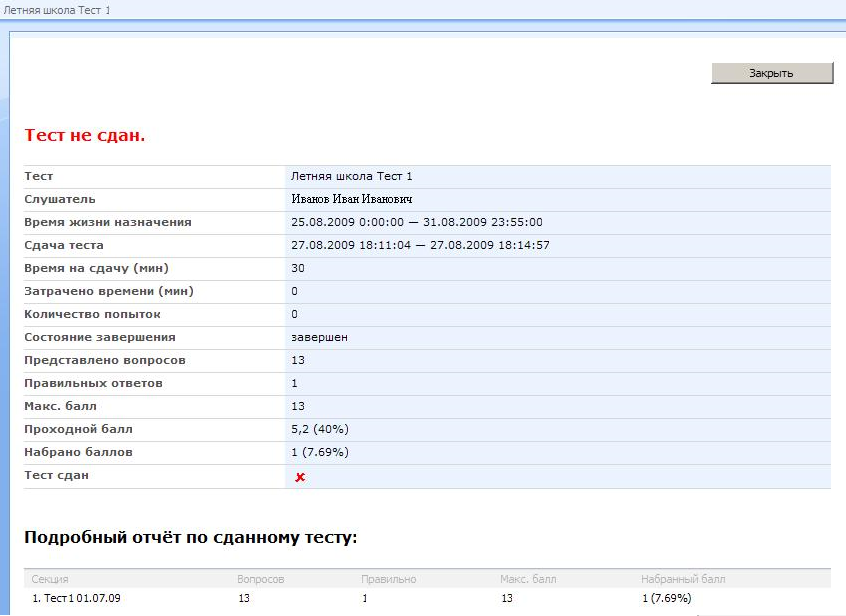
Прежде чем мы углубимся, давайте сначала рассмотрим стандартный одномерный набор данных, который мы можем использовать в качестве контекста для этого руководства.
Остановить изучение временных рядов Прогнозирование
медленно !Пройдите мой бесплатный 7-дневный курс электронной почты и узнайте, как начать работу (с образцом кода).
Нажмите, чтобы зарегистрироваться, а также получить бесплатную электронную версию курса в формате PDF.
Начните БЕСПЛАТНЫЙ мини-курс прямо сейчас!
Набор данных о ежедневных женских родах
Этот набор данных описывает количество ежедневных рождений женского пола в Калифорнии в 1959 году.
Единицы являются подсчетом, и имеется 365 наблюдений.Источником набора данных является Newton (1988).
Загрузите набор данных и поместите его в текущий рабочий каталог с именем файла « daily-total-female-births.csv ».
Мы можем загрузить набор данных в виде серии Pandas.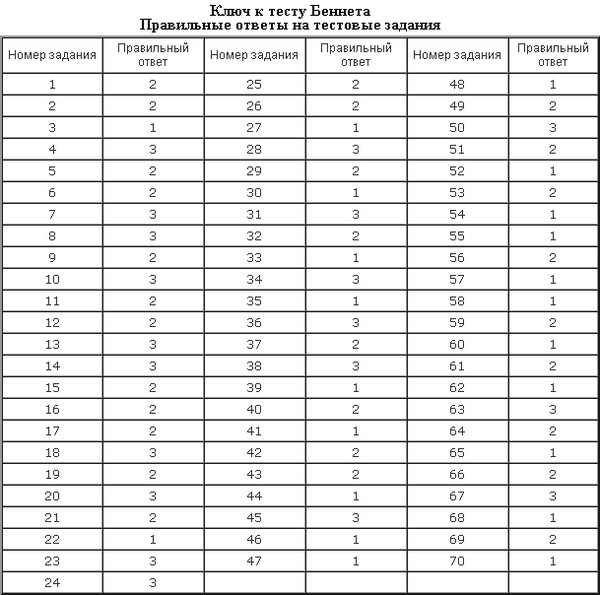 Фрагмент ниже загружает и отображает набор данных.
Фрагмент ниже загружает и отображает набор данных.
из pandas импортировать read_csv из matplotlib импортировать pyplot серия = read_csv(‘ежедневное количество женских рождений.csv’, заголовок = 0, index_col = 0) печать (серия.голова()) серия.сюжет() pyplot.show ()
из pandas import read_csv из matplotlib import pyplot series = read_csv(‘daily-total-female-births.csv’, header=0, index_col=0) print(series.head()) серия.plot() pyplot.show() |
При выполнении примера печатаются первые 5 строк набора данных.
Дата 1959-01-01 35 1959-01-02 32 1959-01-03 30 1959-01-04 31 1959-01-05 44
Дата 1959-01-01 35 1959-01-02 32 1959-01-03 30 1959-01-04 31 1959-01-05 44 |
Затем ряд отображается в виде линейного графика.
Линейный график набора данных о рождении женщин за день
1. Выберите модель прогноза временных рядов
Необходимо выбрать модель.
Именно здесь основная часть усилий будет направлена на подготовку данных, выполнение анализа и, в конечном счете, на выбор модели и гиперпараметров модели, которые лучше всего отражают отношения в данных.
В этом случае мы можем произвольно выбрать модель авторегрессии (AR) с запаздыванием 6 в разностном наборе данных.
Мы можем продемонстрировать эту модель ниже.
Сначала данные преобразуются путем дифференцирования, при этом каждое наблюдение преобразуется как:
значение(т) = набл(т) — набл(т — 1)
значение(t) = наб(t) — набл(t — 1) |
Затем модель AR(6) обучается на 66% исторических данных. Коэффициенты регрессии, изученные моделью, извлекаются и используются для построения прогнозов скользящим образом по набору тестовых данных.
По мере выполнения каждого временного шага в тестовом наборе данных прогноз делается с использованием коэффициентов и сохраняется. Затем фактическое наблюдение для временного шага становится доступным и сохраняется для использования в качестве переменной запаздывания для будущих прогнозов.
# подогнать и оценить модель дополненной реальности
из pandas импортировать read_csv
из matplotlib импортировать pyplot
из statsmodels.tsa.ar_model импортировать AutoReg
из sklearn.metrics импорта mean_squared_error
импортировать numpy
из математического импорта sqrt # создаем разностное преобразование набора данных
разница определения (набор данных):
разница = список ()
для i в диапазоне (1, len (набор данных)):
значение = набор данных [i] — набор данных [i — 1]
диф.добавить (значение)
вернуть numpy.array(diff) # Сделать прогноз, дать коэффициенты регрессии и запаздывание наблюдений
def прогнозировать (коэффициент, история):
yhat = коэффициент [0]
для i в диапазоне (1, len (коэффициент)):
yhat += коэффициент[i] * история[-i]
вернуть их series = read_csv(‘Daily-total-female-births.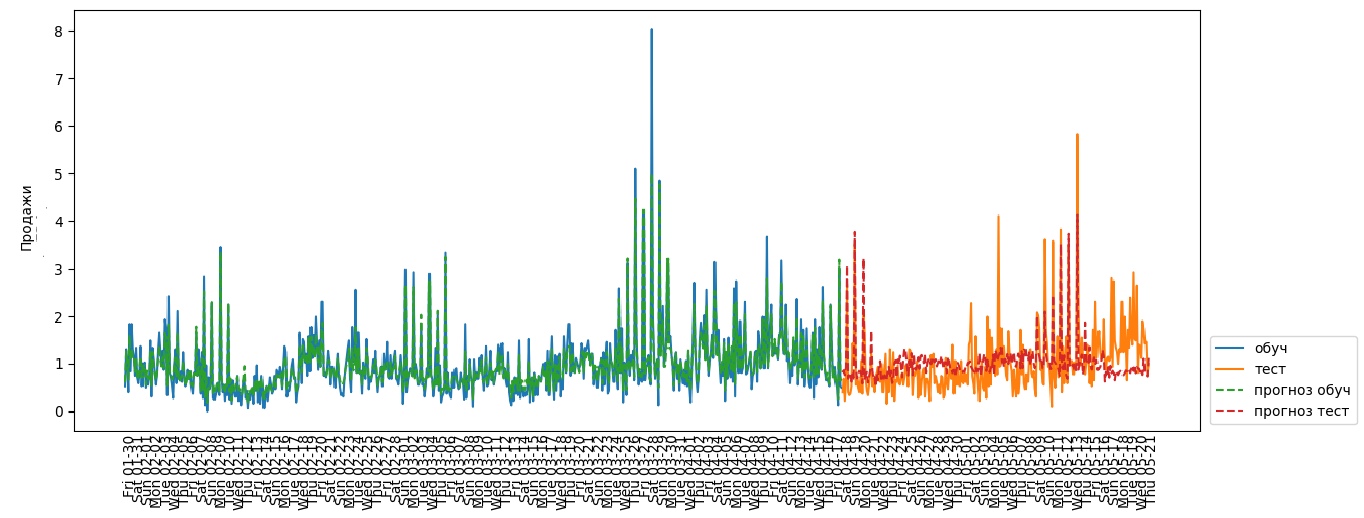 csv’, header=0, index_col=0, parse_dates=True, сжатия=True)
# разделить набор данных
X = разница (серия.значения)
размер = интервал (длина (X) * 0,66)
поезд, тест = X[0:размер], X[размер:]
# тренируем авторегрессию
окно = 6
модель = AutoReg (поезд, лаги = 6)
модель_подходит = модель.соответствовать()
коэф = model_fit.params
# продвигаться вперед по временным шагам в тесте
history = [train[i] для i в диапазоне (len(train))]
прогнозы = список()
для t в диапазоне (len (тест)):
yhat = предсказать (коэффициент, история)
наблюдения = тест [t]
предсказания .append (yhat)
history.append(наблюдения)
rmse = sqrt (mean_squared_error (тест, прогнозы))
print(‘Проверка RMSE: %.3f’ % rmse)
# участок
pyplot.plot (тест)
pyplot.plot (прогнозы, цвет = ‘красный’)
pyplot.show ()
csv’, header=0, index_col=0, parse_dates=True, сжатия=True)
# разделить набор данных
X = разница (серия.значения)
размер = интервал (длина (X) * 0,66)
поезд, тест = X[0:размер], X[размер:]
# тренируем авторегрессию
окно = 6
модель = AutoReg (поезд, лаги = 6)
модель_подходит = модель.соответствовать()
коэф = model_fit.params
# продвигаться вперед по временным шагам в тесте
history = [train[i] для i в диапазоне (len(train))]
прогнозы = список()
для t в диапазоне (len (тест)):
yhat = предсказать (коэффициент, история)
наблюдения = тест [t]
предсказания .append (yhat)
history.append(наблюдения)
rmse = sqrt (mean_squared_error (тест, прогнозы))
print(‘Проверка RMSE: %.3f’ % rmse)
# участок
pyplot.plot (тест)
pyplot.plot (прогнозы, цвет = ‘красный’)
pyplot.show ()
1 2 2 3 4 5 6 7 8 70002 8 9 10 11 12 13 12 14 13 14 15 16 17 18 19 20 20 21 22 23 240002 23 25 240002 26 25 27 26 27 28 29 28 30 31 30 32 31 32 33 34 34 36 37 38 38 39 39 40 41 42 43 43 44 45 46 47 | # подобрать и оценить модель AR из pandas import read_csv из matplotlib import pyplot из statsmodels. from sklearn.metrics import mean_squared_error import numpy from math import sqrt
# создайте разностное преобразование набора данных 02()defdif0(0dataset): для i в диапазоне (1, len (набор данных)): значение = набор данных [i] — набор данных [i — 1] diff.append (значение) return numpy.array (diff)
# Сделать прогноз, дать коэффициенты регрессии и отставание наблюдений def Predict(coef, history): yhat = coef[0] for i in range(1, len(coef)): yhat += coef [i] * history[-i] return yhat
series = read_csv(‘ежедневное-общее-женское-рождений.csv’, header=0, index_col=0, parse_dates=True, сжатия=True) # разделить набор данных X = разность(series.values) size = int(len(X) * 0.66) train , test = X[0:size], X[size:] # авторегрессия поезда window = 6 model = AutoReg(train, lags=6) model_fit = model. coef = model_fit.params # шаг вперед по шагам времени в тесте )): yhat = прогноз(коэффициент, история) obs = тест[t] прогнозы.append(yhat) history.append(obs) rmse = sqrt(mean_squared_error(тест, предсказания)) print(‘Test RMSE: %.3f’ % rmse) # plot pyplot.plot( тест) pyplot.plot(предсказания, цвет=’красный’) pyplot.show() |
 tsa.ar_model import AutoReg
tsa.ar_model import AutoReg fit()
fit()При выполнении примера сначала печатается среднеквадратическая ошибка (RMSE) прогнозов, которая в среднем составляет около 7 рождений.
Это то, насколько хорошо мы ожидаем, что модель в среднем будет работать при прогнозировании новых данных.
Наконец, создается график, показывающий фактические наблюдения в тестовом наборе данных (синий) по сравнению с прогнозами (красный).
Прогнозы и фактические ежедневные данные о рождении женщин Линейный график
Возможно, это не самая лучшая модель, которую мы могли бы разработать для этой проблемы, но она разумна и искусна.
2. Завершение и сохранение модели прогноза временных рядов
После того, как модель выбрана, мы должны ее доработать.
Это означает сохранение существенной информации, полученной моделью, чтобы нам не приходилось создавать ее заново каждый раз, когда требуется прогноз.
Это включает в себя сначала обучение модели на всех доступных данных, а затем сохранение модели в файл.
Реализации моделей временных рядов statsmodels обеспечивают встроенную возможность сохранения и загрузки моделей путем вызова save() и load() для подходящего объекта AutoRegResults .
Например, приведенный ниже код будет обучать модель AR(6) на всем наборе данных о рождении женщин и сохранять ее с помощью встроенной функции save() , которая, по сути, выберет объект AutoRegResults .
Также должны быть сохранены разностные обучающие данные, как для переменных запаздывания, необходимых для создания прогноза, так и для знания количества просмотренных наблюдений, требуемых функцией прогноза() объекта AutoRegResults .
Наконец, нам нужно иметь возможность преобразовать измененный набор данных обратно в исходную форму. Для этого мы должны отслеживать последнее фактическое наблюдение. Это делается для того, чтобы к нему можно было добавить прогнозируемое разностное значение.
# подогнать модель AR и сохранить всю модель в файл
из pandas импортировать read_csv
из statsmodels.tsa.ar_model импортировать AutoReg
импортировать numpy # создаем разностное преобразование набора данных
разница определения (набор данных):
разница = список ()
для i в диапазоне (1, len (набор данных)):
значение = набор данных [i] — набор данных [i — 1]
diff.append(значение)
вернуть numpy.array(diff) # загрузить набор данных
series = read_csv(‘ежедневное общее число рождений женского пола.csv’, заголовок = 0, index_col = 0, parse_dates = True, сжатие = True)
X = разница (серия.значения)
# подходящая модель
модель = AutoReg (X, лаги = 6)
model_fit = модель.fit()
# сохранить модель в файл
model_fit. save(‘ar_model.pkl’)
# сохранить отличающийся набор данных
numpy.save(‘ar_data.npy’, X)
# сохранить последний объект
numpy.save(‘ar_obs.npy’, [series.values[-1]])
save(‘ar_model.pkl’)
# сохранить отличающийся набор данных
numpy.save(‘ar_data.npy’, X)
# сохранить последний объект
numpy.save(‘ar_obs.npy’, [series.values[-1]])
1 2 2 3 4 5 6 7 8 70002 8 9 10 11 12 13 12 14 13 14 15 16 17 18 19 20 21 22 23 24 25 | # подогнать модель AR и сохранить всю модель в файл из pandas import read_csv из statsmodels.tsa.ar_model import AutoReg import numpy
# создать разностное преобразование набора данных def different(dataset): diff = list() for i in range(1, len(dataset)) : value = набор данных[i] — набор данных[i — 1] diff.append(value) return numpy.
# загрузить набор данных series = read_csv(‘daily-total(‘daily-total -female-births.csv’, header=0, index_col=0, parse_dates=True, сжатия=True) X = разность(series.values) # подходящая модель model = AutoReg(X, lags=6) model_fit = model.fit() # сохранить модель в файл model_fit.save(‘ar_model.pkl’) # сохранить разностный набор данных numpy.save(‘ar_data.npy’, X) # сохранить последний ob numpy.save(‘ar_obs.npy’, [series.values[-1]]) |
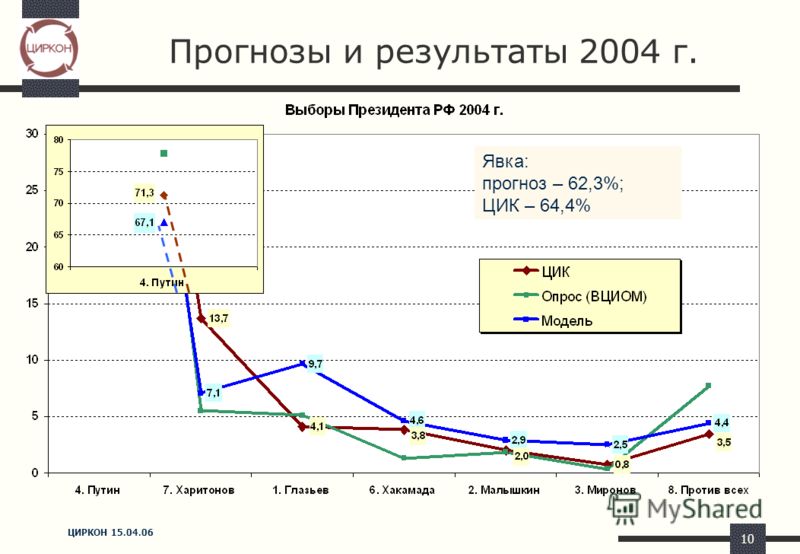 array(diff)
array(diff)Этот код создаст файл ar_model.pkl , который вы сможете загрузить позже и использовать для прогнозирования.
Весь набор обучающих данных сохраняется как ar_data.npy , а последнее наблюдение сохраняется в файле ar_obs.npy как массив с одним элементом.
Функция NumPy save() используется для сохранения различных данных обучения и наблюдения. Затем функцию load() можно использовать для загрузки этих массивов позже.
Фрагмент ниже загрузит модель, разностные данные и последнее наблюдение.
# загружаем модель дополненной реальности из файла из статмоделей.tsa.ar_model импорт AutoRegResults импортировать numpy загружен = AutoRegResults.load(‘ar_model.pkl’) печать (загруженные.параметры) данные = numpy.load(‘ar_data.npy’) last_ob = numpy.load(‘ar_obs.npy’) распечатать (последний_об)
# загрузить модель AR из файла из statsmodels.tsa.ar_model import AutoRegResults import numpy loaded = AutoRegResults.load(‘ar_model.pkl’) print(loaded.params) data = numpy.load(‘ar_data.npy’) last_ob = numpy.load(‘ar_obs.npy’) print(last_ob) |
При выполнении примера распечатываются коэффициенты и последнее наблюдение.
[ 0,12129822 -0,75275857 -0,612367 -0,51097172 -0,4176669 -0,32116469 -0,23412997] [50]
[ 0,12129822 -0,75275857 -0,612367 -0,51097172 -0. -0,23412997] [50] |
Я думаю, что это хорошо для большинства случаев, но также довольно тяжело. Вы можете изменить API statsmodels.
Я предпочитаю работать с коэффициентами модели напрямую, как в случае выше, оценивая модель с помощью скользящего прогноза.
В этом случае вы можете просто сохранить коэффициенты модели, а затем загрузить их и сделать прогнозы.
В приведенном ниже примере сохраняются только коэффициенты из модели, а также минимальные разностные значения запаздывания, необходимые для выполнения следующего прогноза, и последнее наблюдение, необходимое для преобразования следующего сделанного прогноза.
# подогнать модель AR и вручную сохранить коэффициенты в файл
из pandas импортировать read_csv
из statsmodels.tsa.ar_model импортировать AutoReg
импортировать numpy # создаем разностное преобразование набора данных
разница определения (набор данных):
разница = список ()
для i в диапазоне (1, len (набор данных)):
значение = набор данных [i] — набор данных [i — 1]
diff. append(значение)
вернуть numpy.array(diff) # загрузить набор данных
series = read_csv(‘ежедневное общее число рождений женского пола.csv’, заголовок = 0, index_col = 0, parse_dates = True, сжатие = True)
X = разница (серия.значения)
# подходящая модель
размер_окна = 6
модель = AutoReg (X, лаги = размер_окна)
model_fit = модель.fit()
# сохранить коэффициенты
коэф = model_fit.params
numpy.save(‘man_model.npy’, коэф.)
# сохранить отставание
отставание = X[-размер_окна:]
numpy.save(‘man_data.npy’, отставание)
# сохранить последний объект
numpy.save(‘man_obs.npy’, [series.values[-1]])
append(значение)
вернуть numpy.array(diff) # загрузить набор данных
series = read_csv(‘ежедневное общее число рождений женского пола.csv’, заголовок = 0, index_col = 0, parse_dates = True, сжатие = True)
X = разница (серия.значения)
# подходящая модель
размер_окна = 6
модель = AutoReg (X, лаги = размер_окна)
model_fit = модель.fit()
# сохранить коэффициенты
коэф = model_fit.params
numpy.save(‘man_model.npy’, коэф.)
# сохранить отставание
отставание = X[-размер_окна:]
numpy.save(‘man_data.npy’, отставание)
# сохранить последний объект
numpy.save(‘man_obs.npy’, [series.values[-1]])
1 2 2 3 4 5 6 7 8 70002 8 9 10 11 12 13 12 14 13 14 15 16 17 18 19 20 20 21 22 23 240002 23 24 25 26 27 28 | # подогнать модель AR и вручную сохранить коэффициенты в файл из pandas import read_csv из statsmodels. import numpy
# создать разностное преобразование набора данных def different(dataset): diff = list() for i in range(1, len(dataset)) : value = набор данных[i] — набор данных[i — 1] diff.append(value) return numpy.array(diff)
# загрузить набор данных series = read_csv(‘daily-total(‘daily-total -female-births.csv’, header=0, index_col=0, parse_dates=True, сжатия=True) X = разность(series.values) # fit model window_size = 6 model = AutoReg(X, lags=window_size) model_fit = model.fit() # сохранить коэффициенты coef = model_fit.params 3 (‘man_model.npy’, coef)# сохранить отставание lag = X[-window_size:] numpy.save(‘man_data.npy’, lag) # сохранить последний объект numpy.save (‘man_obs.npy’, [series.values[-1]]) |
 tsa.ar_model import AutoReg
tsa.ar_model import AutoReg Коэффициенты сохранены в локальном файле man_model. npy , история задержки сохраняется в файле man_data.npy , а последнее наблюдение сохраняется в файле man_obs.npy .
npy , история задержки сохраняется в файле man_data.npy , а последнее наблюдение сохраняется в файле man_obs.npy .
Затем эти значения можно снова загрузить следующим образом:
# загрузить сохраненную вручную модель из файла импортировать numpy коэф = numpy.load(‘man_model.npy’) печать (коэффициент) отставание = numpy.load(‘man_data.npy’) печать (отставание) last_ob = numpy.load(‘man_obs.npy’) распечатать (последний_об)
# загрузить сохраненную вручную модель из файла import numpy coef = numpy.load(‘man_model.npy’) print(coef) lag = numpy.load(‘man_data.npy’) print(lag) last_ob = numpy.load(‘man_obs.npy’) печать (последний_об) |
При выполнении этого примера загруженные данные распечатываются для просмотра. Мы видим, что коэффициенты и последнее наблюдение соответствуют выходным данным из предыдущего примера.
[ 0,12129822 -0,75275857 -0,612367 -0,51097172 -0,4176669 -0,32116469 -0,23412997] [-10 3 15 -4 7 -5] [50]
[ 0.12129822 -0.75275857 -0.612367 -0.51097172 -0.51097172 -0.4176669 -0.321164669 -0.32116469 -0.23412997] [-10 3 15 -4 7 -5] [50] |
Теперь, когда мы знаем, как сохранить готовую модель, мы можем использовать ее для составления прогнозов.
3. Сделайте прогноз временного ряда
Создание прогноза включает загрузку сохраненной модели и оценку наблюдения на следующем временном шаге.
Если объект AutoRegResults был сериализован, мы можем использовать функцию predict() для прогнозирования следующего периода времени.
В приведенном ниже примере показано, как можно предсказать следующий период времени.
Модель, обучающие данные и последнее наблюдение загружаются из файла.
Период указывается в функции predict() как следующий временной индекс после окончания обучающего набора данных. Этот индекс может храниться непосредственно в файле вместо хранения всех обучающих данных, что может быть более эффективным.
Этот индекс может храниться непосредственно в файле вместо хранения всех обучающих данных, что может быть более эффективным.
Прогноз сделан в контексте разностного набора данных.Чтобы вернуть прогноз в исходные единицы, его необходимо добавить к последнему известному наблюдению.
# загрузить модель дополненной реальности из файла и сделать одношаговый прогноз из statsmodels.tsa.ar_model импортировать AutoRegResults импортировать numpy # загрузить модель модель = AutoRegResults.load(‘ar_model.pkl’) данные = numpy.load(‘ar_data.npy’) last_ob = numpy.load(‘ar_obs.npy’) # сделать прогноз прогнозы = model.predict (начало = длина (данные), конец = длина (данные)) # преобразование предсказания yhat = прогнозы[0] + last_ob[0] print(‘Предсказание: %f’ % yhat)
# загрузить модель AR из файла и сделать одношаговый прогноз из statsmodels.tsa.ar_model import AutoRegResults import numpy # модель загрузки model = AutoRegResults. data = numpy.load(‘ar_data.npy’) last_ob = numpy.load( ‘ar_obs.npy’) # сделать предсказание предсказания = model.predict(start=len(data), end=len(data)) # преобразовать предсказание yhat = предсказания[0] + last_ob[0 ] print(‘Прогноз: %f’ % yhat) |
 load(‘ar_model.pkl’)
load(‘ar_model.pkl’)Выполнение примера распечатывает прогноз.
Мы также можем использовать аналогичный прием, чтобы загрузить необработанные коэффициенты и сделать прогноз вручную.
Полный пример приведен ниже.
# загрузить коэффициенты и из файла и сделать прогноз вручную импортировать numpy def прогнозировать (коэффициент, история): yhat = коэффициент [0] для i в диапазоне (1, len (коэффициент)): yhat += коэффициент[i] * история[-i] вернуть их # загрузить модель коэф = numpy.load(‘man_model.npy’) отставание = numpy.load(‘man_data.нпи’) last_ob = numpy.load(‘man_obs.npy’) # сделать прогноз прогноз = прогноз (коэффициент, отставание) # преобразование предсказания yhat = предсказание + last_ob[0] print(‘Предсказание: %f’ % yhat)
1 2 2 3 4 5 6 7 8 70002 8 9 10 11 12 13 12 14 13 14 15 16 17 18 | # загрузить коэффициенты и из файла и сделать прогноз вручную )): yhat += coef[i] * history[-i] return yhat
# модель загрузки coef = numpy. lag = numpy.load(‘man_data.npy’) last_ob = numpy.load(‘man_obs.npy’) # сделать прогноз ) # Преобразование предсказания yhat = предсказание + last_ob[0] print(‘Предсказание: %f’ % yhat) |
 load(‘man_model.npy’)
load(‘man_model.npy’)Запустив пример, мы получим тот же прогноз, которого и ожидали, учитывая, что базовая модель и метод для создания прогноза одинаковы.
4. Обновление модели прогноза
Наша работа не сделана.
Как только станет доступным следующее реальное наблюдение, мы должны обновить данные, связанные с моделью.
В частности, мы должны обновить:
- Разный набор обучающих данных, используемый в качестве входных данных для последующего прогнозирования.
- Последнее наблюдение, предоставляющее контекст для прогнозируемого разностного значения.
Предположим, что следующее фактическое наблюдение в серии было 48.
Новое наблюдение сначала должно быть разным с последним наблюдением. Затем его можно сохранить в списке разностных наблюдений. Наконец, значение может быть сохранено как последнее наблюдение.
В случае сохраненной модели AR мы можем обновить файлы ar_data.npy и ar_obs.npy . Полный пример приведен ниже:
# обновить данные для модели AR с новым значением obs импортировать numpy # получить реальное наблюдение наблюдение = 48 # загрузить сохраненные данные данные = число.загрузить(‘ar_data.npy’) last_ob = numpy.load(‘ar_obs.npy’) # обновить и сохранить различное наблюдение diffed = наблюдение — last_ob[0] данные = numpy.append (данные, [diffed], ось = 0) numpy.save(‘ar_data.npy’, данные) # обновить и сохранить реальное наблюдение last_ob[0] = наблюдение numpy.save(‘ar_obs.npy’, last_ob)
# обновить данные для модели AR с новым obs import numpy # получить реальное наблюдение наблюдение = 48 # загрузить сохраненные данные data = numpy.load(‘ar_data.npy’) last_ob = numpy.load(‘ar_obs.npy’) # обновить и сохранить разностное наблюдение [diffed], axis=0) numpy.save(‘ar_data.npy’, data) # обновить и сохранить реальное наблюдение last_ob[0] = наблюдение numpy.save(‘ar_obs.npy’, last_ob) |
Мы можем внести такие же изменения в файлы данных для ручного случая.В частности, мы можем обновить man_data.npy и man_obs.npy соответственно.
Полный пример приведен ниже.
# обновить данные для ручной модели новым значением obs импортировать numpy # получить реальное наблюдение наблюдение = 48 # обновить и сохранить различное наблюдение отставание = numpy.load(‘man_data.npy’) last_ob = numpy.load(‘man_obs.npy’) diffed = наблюдение — last_ob[0] отставание = numpy.append (отставание [1:], [diffed], ось = 0) тупой.сохранить (‘man_data.npy’, отставание) # обновить и сохранить реальное наблюдение last_ob[0] = наблюдение numpy.save(‘man_obs.npy’, last_ob)
# обновить данные для ручной модели с новыми наблюдениями import numpy # получить реальное наблюдение ) last_ob = numpy.load(‘man_obs.npy’) diffed = наблюдение — last_ob[0] lag = numpy.append(lag[1:], [diffed], axis=0) numpy.save(‘man_data.npy’, lag) # обновить и сохранить реальное наблюдение |
Мы сосредоточились на одношаговых прогнозах.
Эти методы будут так же легко работать для многоэтапных прогнозов, используя модель повторно и используя прогнозы предыдущих временных шагов в качестве значений задержки ввода для прогнозирования наблюдений для последующих временных шагов.
Рассмотрите возможность сохранения всех наблюдений
Как правило, рекомендуется отслеживать все наблюдения.
Это позволит вам:
- Предоставьте контекст для дальнейшего анализа временных рядов, чтобы понять новые изменения в данных.
- Обучить новую модель в будущем на самых последних данных.
- Проведите ретроспективное тестирование новых и разных моделей, чтобы увидеть, можно ли улучшить производительность.
Для небольших приложений, возможно, вы могли бы хранить необработанные наблюдения в файле вместе с вашей моделью.
Также может быть желательно сохранить коэффициенты модели и требуемые данные запаздывания, а также последнее наблюдение в виде простого текста для удобства просмотра.
Для более крупных приложений, возможно, можно использовать базу данных для хранения наблюдений.
Резюме
В этом руководстве вы узнали, как завершить модель временных рядов и использовать ее для прогнозирования с помощью Python.
В частности, вы узнали:
- Как сохранить модель прогноза временных рядов в файл.
- Как загрузить сохраненный прогноз временного ряда из файла и сделать прогноз.
- Как обновить модель прогноза временных рядов новыми наблюдениями.